HumanML3D Dataset
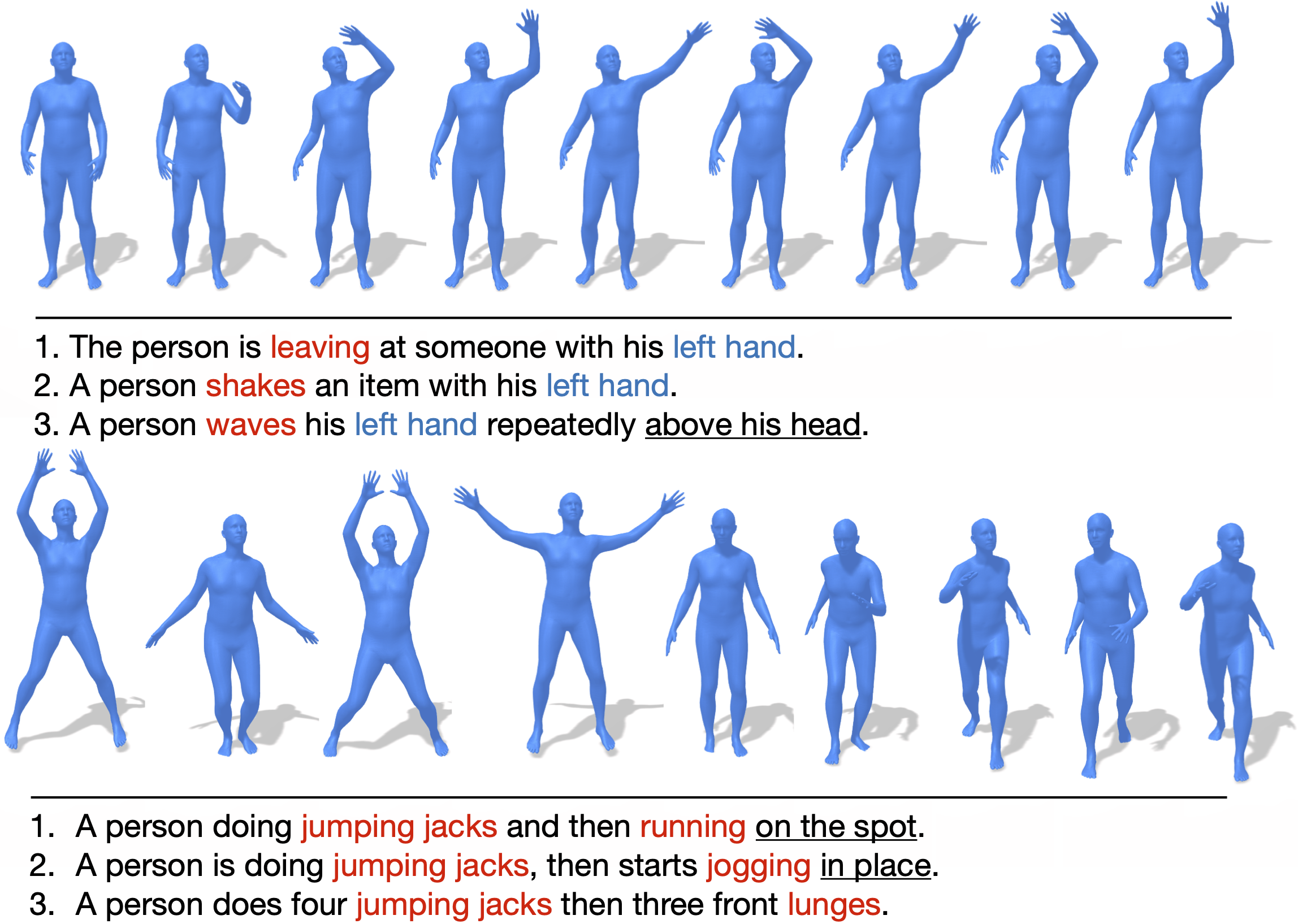
HumanML3D is a 3D human motion-language dataset that originates from a combination of HumanAct12 and Amass dataset. It covers a broad range of human actions such as daily activities (e.g., 'walking', 'jumping'), sports (e.g., 'swimming', 'playing golf'), acrobatics (e.g., 'cartwheel') and artistry (e.g., 'dancing'). Overall, HumanML3D dataset consists of 14,616 motions and 44,970 descriptions composed by 5,371 distinct words. The total length of motions amounts to 28.59 hours. The average motion length is 7.1 seconds, while average description length is 12 words.

Human3.6M Dataset

HumanTOMATO: Text-aligned Whole-body Motion Generation

Top Important Computer Vision Papers for the Week from 27/11 to 03/12, by Youssef Hosni

MoMask: Generative Masked Modeling of 3D Human Motions – arXiv Vanity
GitHub - Mathux/AMASS-Annotation-Unifier: Unify text-motion datasets (like BABEL, HumanML3D, KIT-ML) into a common motion-text representation.

PDF] MotionGPT: Human Motion as a Foreign Language
GitHub - EricGuoICT/HumanML3D

Generate Movement from Text Descriptions with T2M-GPT - Voxel51

VQ-VAE motion reconstruction results on HumanML3D[16] test set. ↑ / ↓

J. Imaging, Free Full-Text

MoMask: Generative Masked Modeling of 3D Human Motions