
Language models might be able to self-correct biases—if you ask them
A study from AI lab Anthropic shows how simple natural-language instructions can steer large language models to produce less toxic content.

Bryan Ackermann on LinkedIn: Korn Ferry and Yoodli Partner to

Limitations and Ethical Considerations of Using ChatGPT

What to Know About AI Self-Correction

Georg Huettenegger on LinkedIn: Language models might be able to
The Full Story of Large Language Models and RLHF

What Is a Language Model, and Why Should You Care?

AI Bias Examples: From Ageism to Racism and Mitigation Strategies
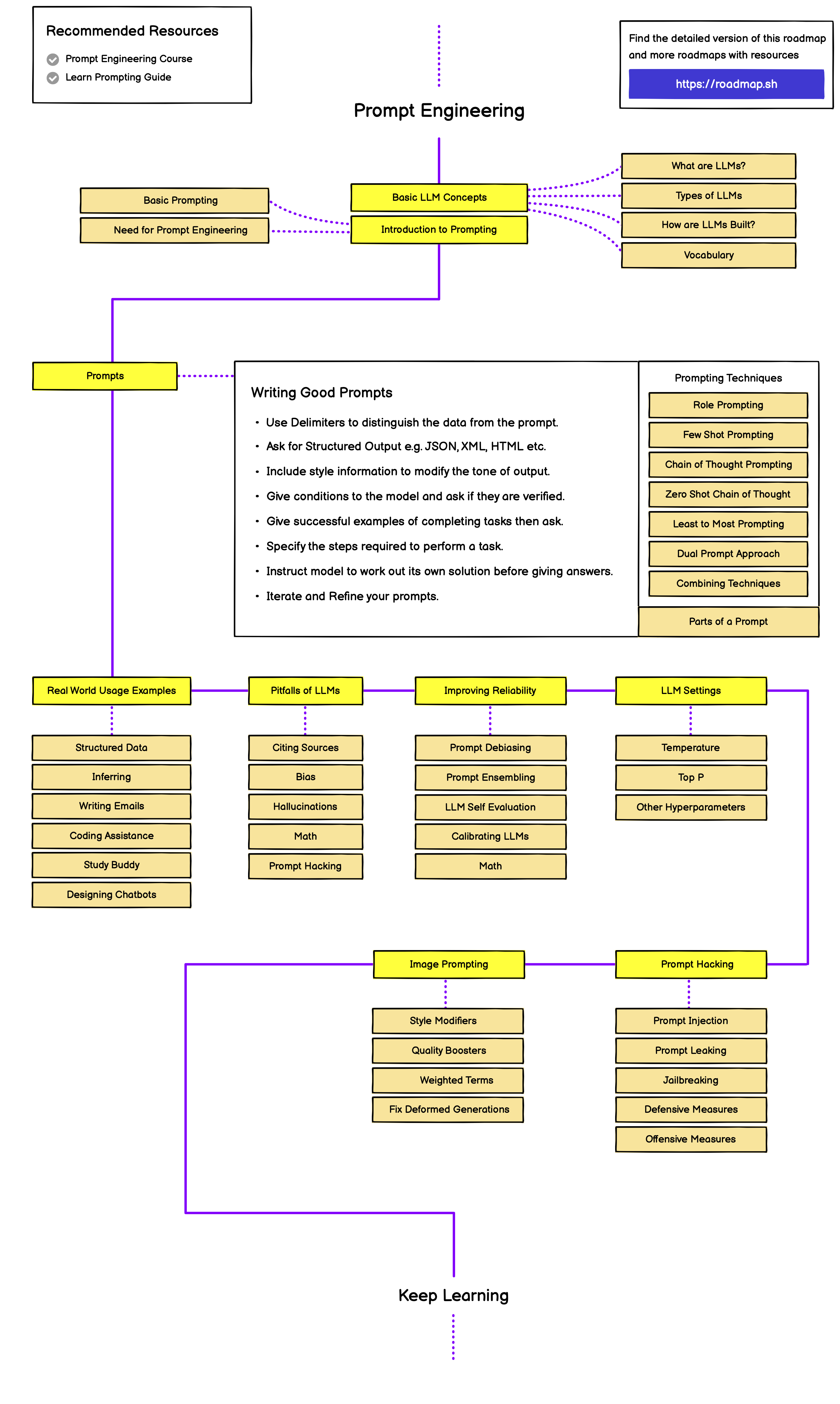
language-models/llm-23.md at master · gopala-kr/language-models

Bryan Ackermann on LinkedIn: Watch Briefings Podcast now!

Georg Huettenegger on LinkedIn: Language models might be able to

Jana Krystofova Mike posted on LinkedIn

Cognitive bias - Wikipedia

language-models/llm-23.md at master · gopala-kr/language-models

Guillermo Preciado (@gpreciado62) / X









