
BERT-Large: Prune Once for DistilBERT Inference Performance
Compress BERT-Large with pruning & quantization to create a version that maintains accuracy while beating baseline DistilBERT performance & compression metrics.
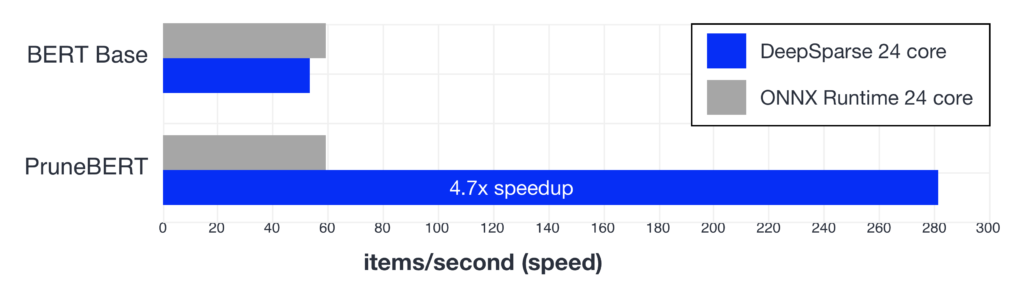
Pruning Hugging Face BERT with Compound Sparsification - Neural Magic
beta) Dynamic Quantization on BERT — PyTorch Tutorials 2.2.1+cu121 documentation
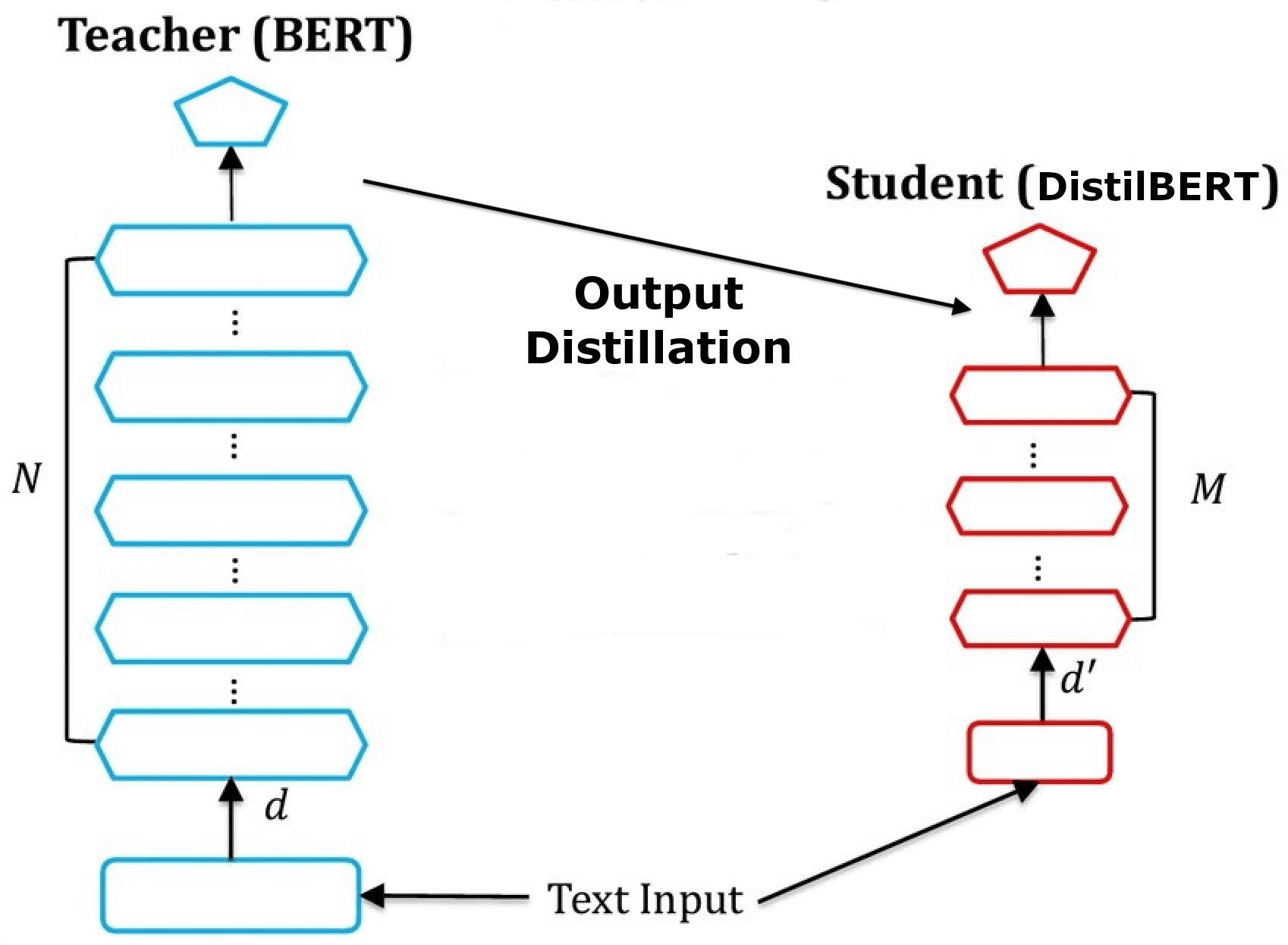
oBERT: Compound Sparsification Delivers Faster Accurate Models for NLP - KDnuggets
Qtile and Qtile-Extras] Catppuccin - Arch / Ubuntu : r/unixporn
Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

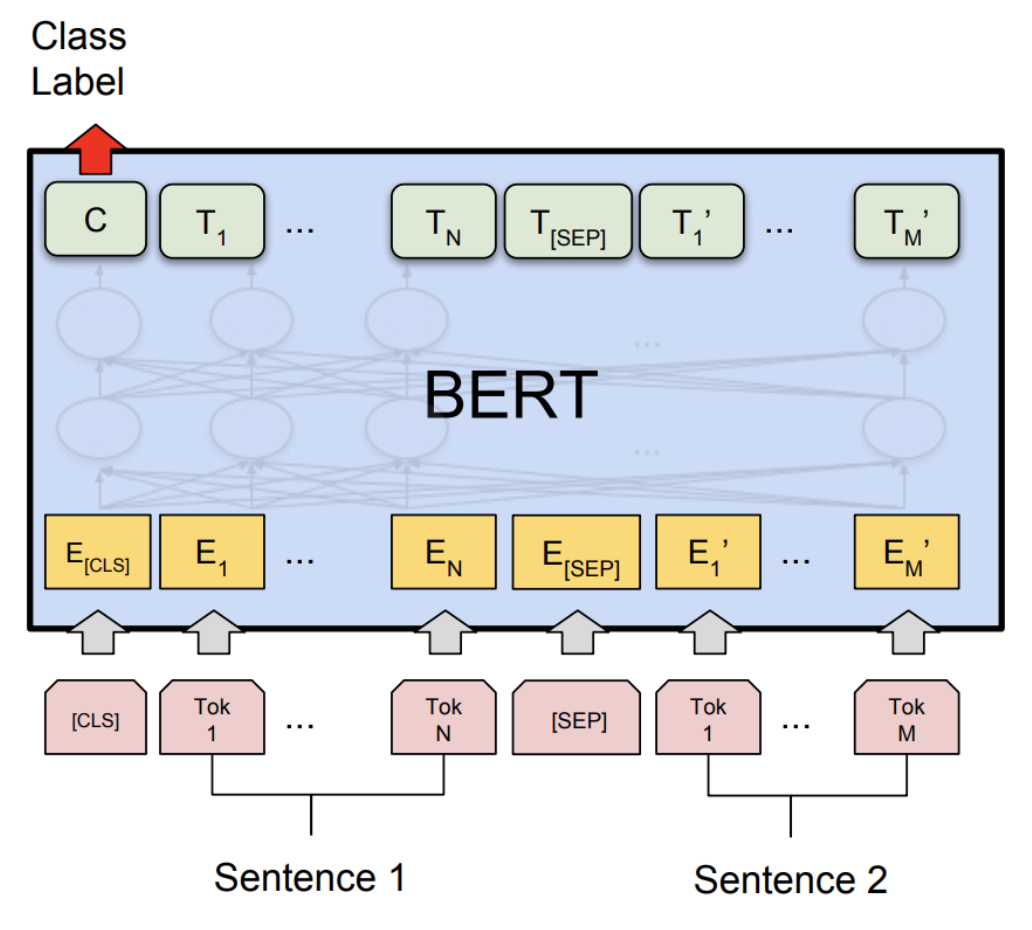
BERT, RoBERTa, DistilBERT, XLNet — which one to use?, by Suleiman Khan, Ph.D.

Intel's Prune Once for All Compression Method Achieves SOTA Compression-to-Accuracy Results on BERT

Dipankar Das on LinkedIn: Intel® Xeon® trains Graph Neural Network
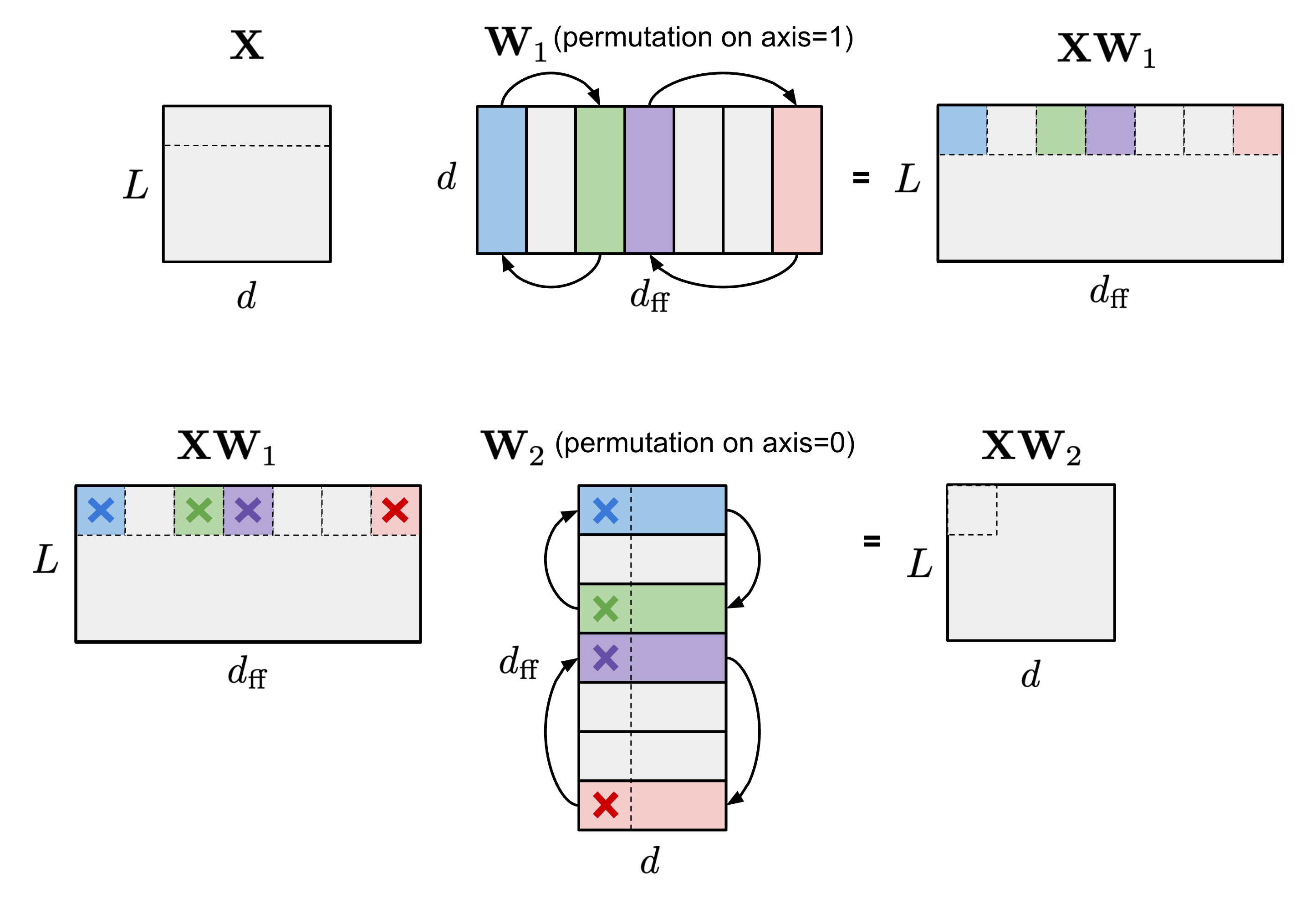
Large Transformer Model Inference Optimization









