Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering
In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

Optimizing Snowflake Queries: Boosting Performance - Beyond the Horizon
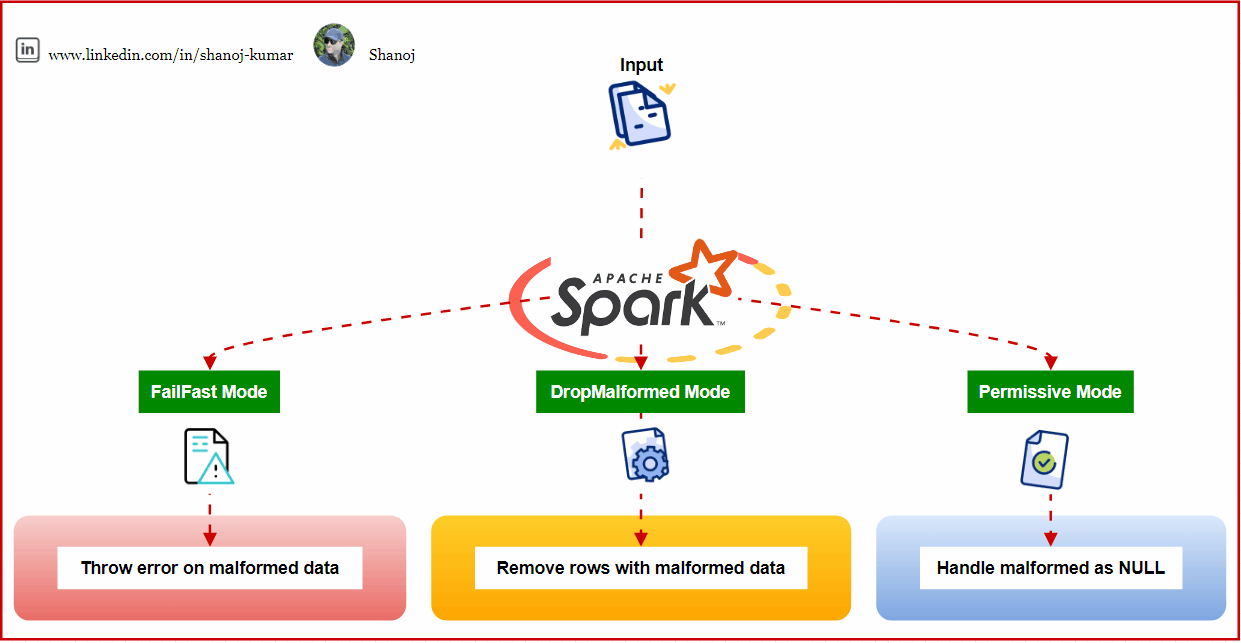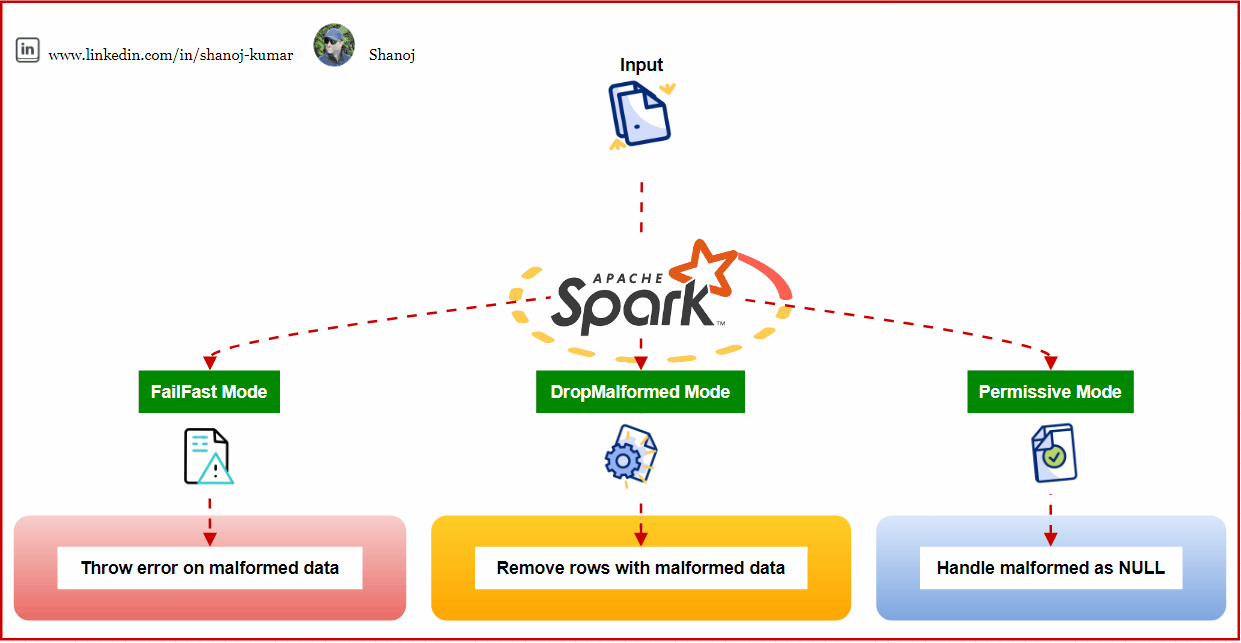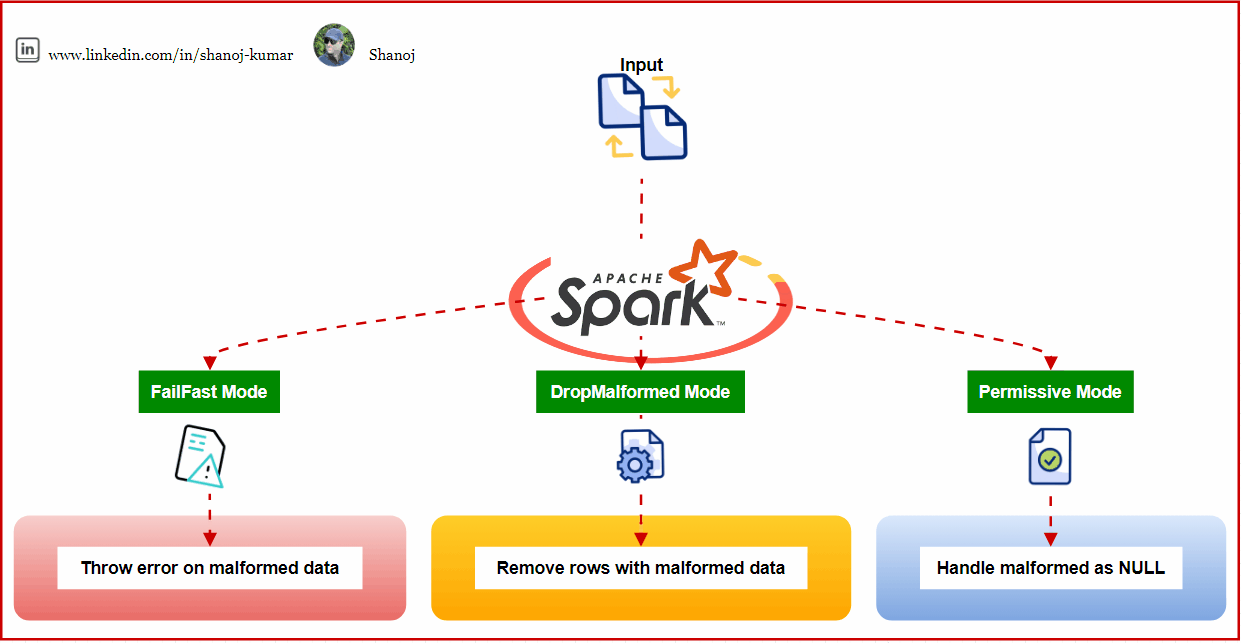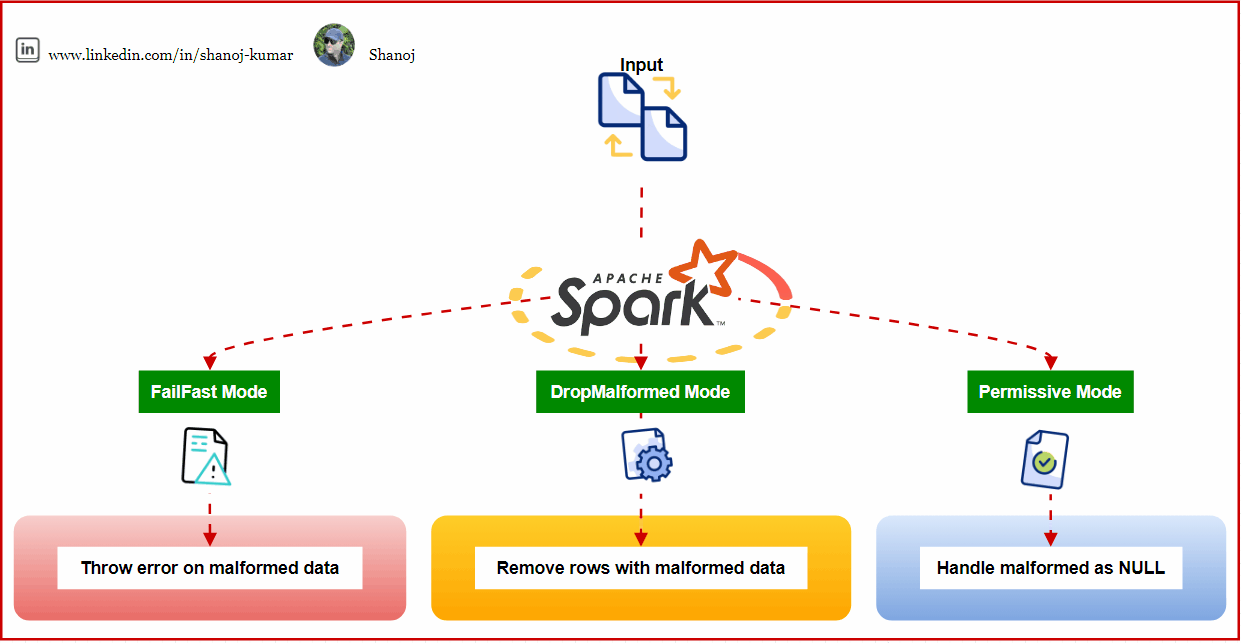
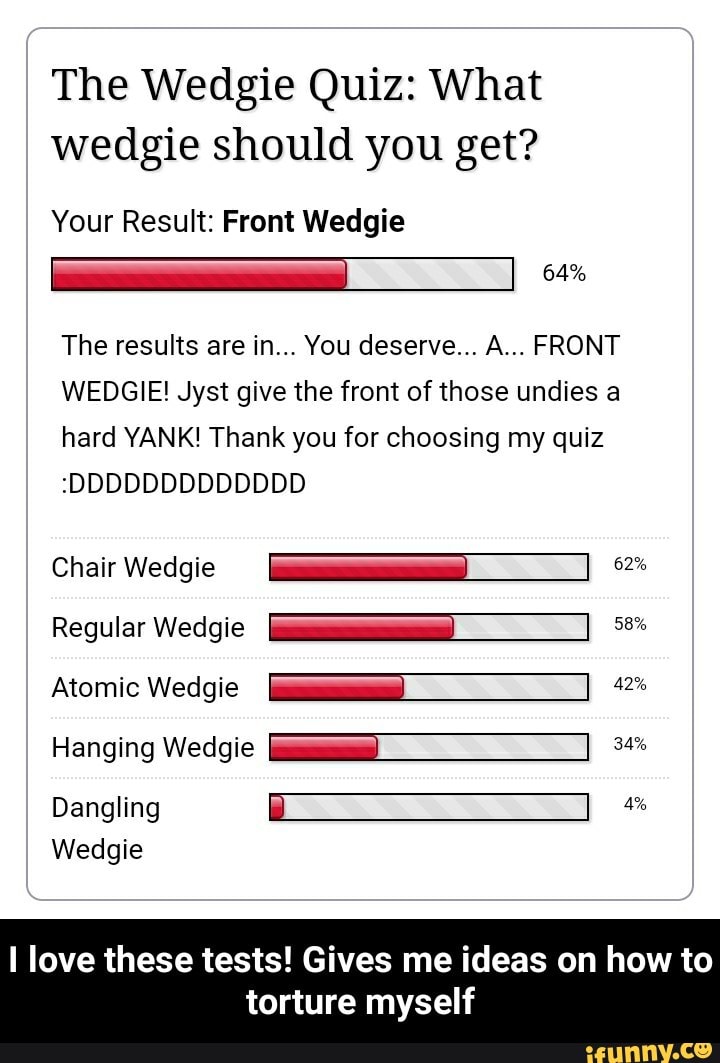
How to Optimize Apache Spark Performance for Big Data Processing

Handling Data Skew in Apache Spark, by Dima Statz

Data engineering and intelligent computing : proceedings of IC3T 2016 978-981-10-3223-3, 9811032238, 978-981-10-3222-6

Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering

Optimization of Spark Data Skew in Big Data Environment
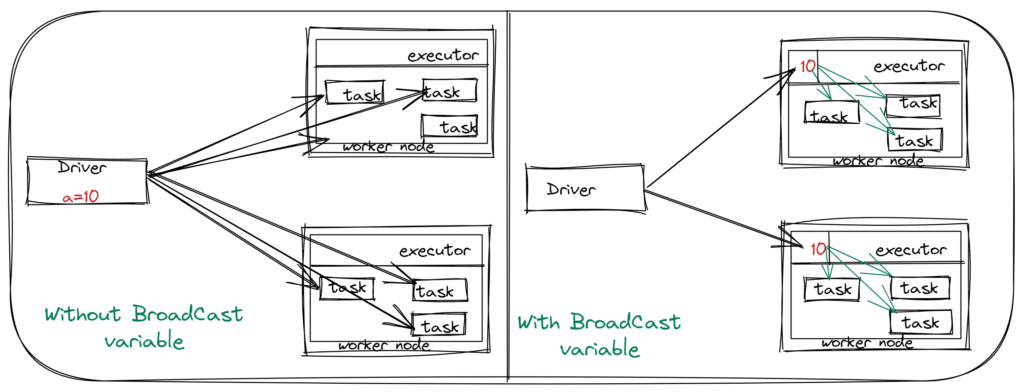
Best Practices and Spark optimization Tips for Data engineers - StatusNeo
Databricks Notebook Promotion using Azure DevOps, by Himansu Sekhar, road to data engineering
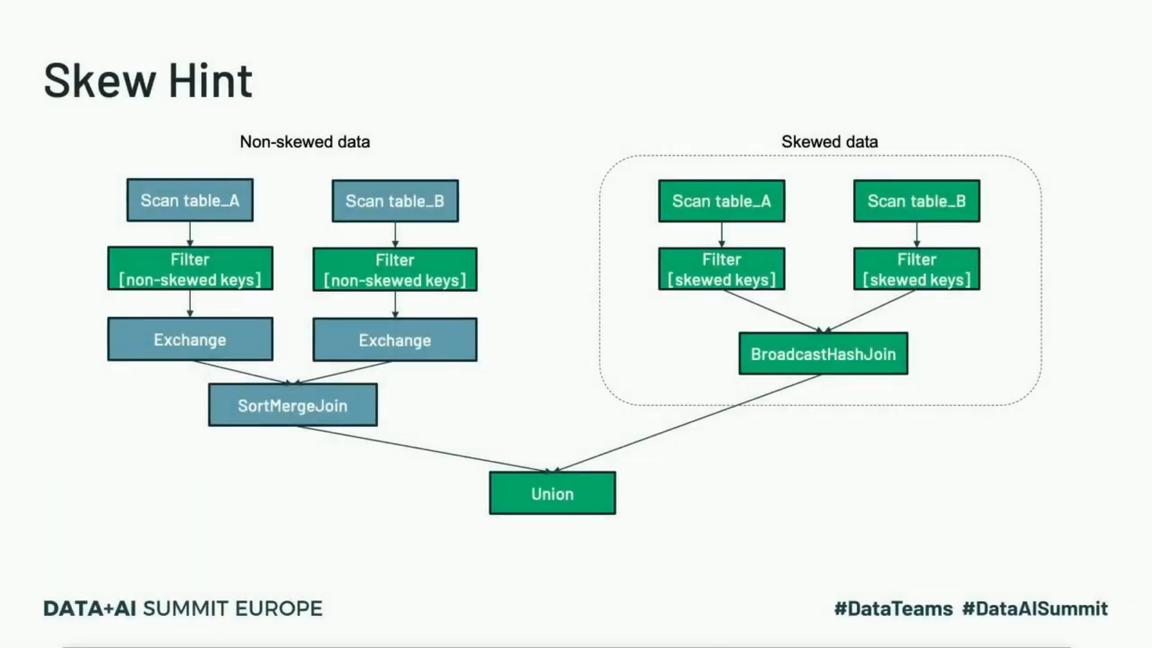
Performance optimization lessons from Spark+AI and Data+AI Summits on - articles about Apache Spark