BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic
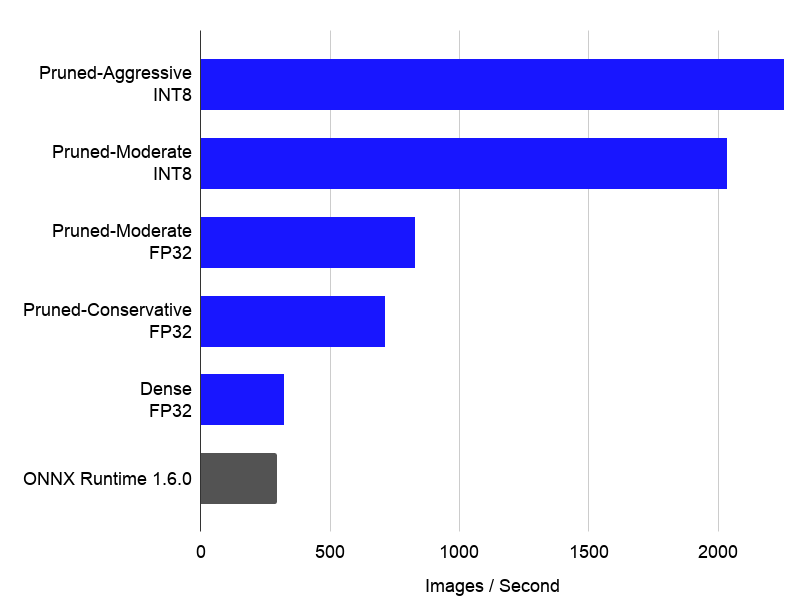
ResNet-50 on CPUs: Sparsifying for Better Performance

Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic

BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic
Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF
Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

Speeding up BERT model inference through Quantization with the Intel Neural Compressor
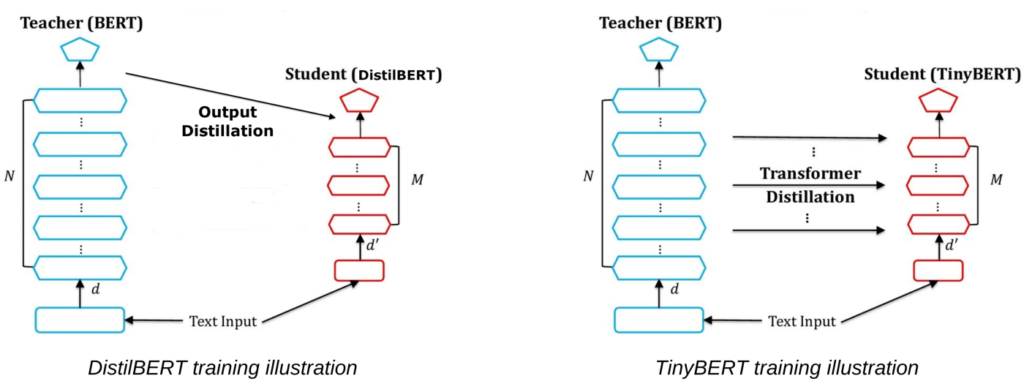
oBERT: GPU-Level Latency on CPUs with 10x Smaller Models

Poor Man's BERT - Exploring layer pruning

arxiv-sanity

Mark Kurtz on LinkedIn: BERT-Large: Prune Once for DistilBERT Inference Performance

Our paper accepted at NeurIPS Workshop on Diffusion Models, kevin chang posted on the topic
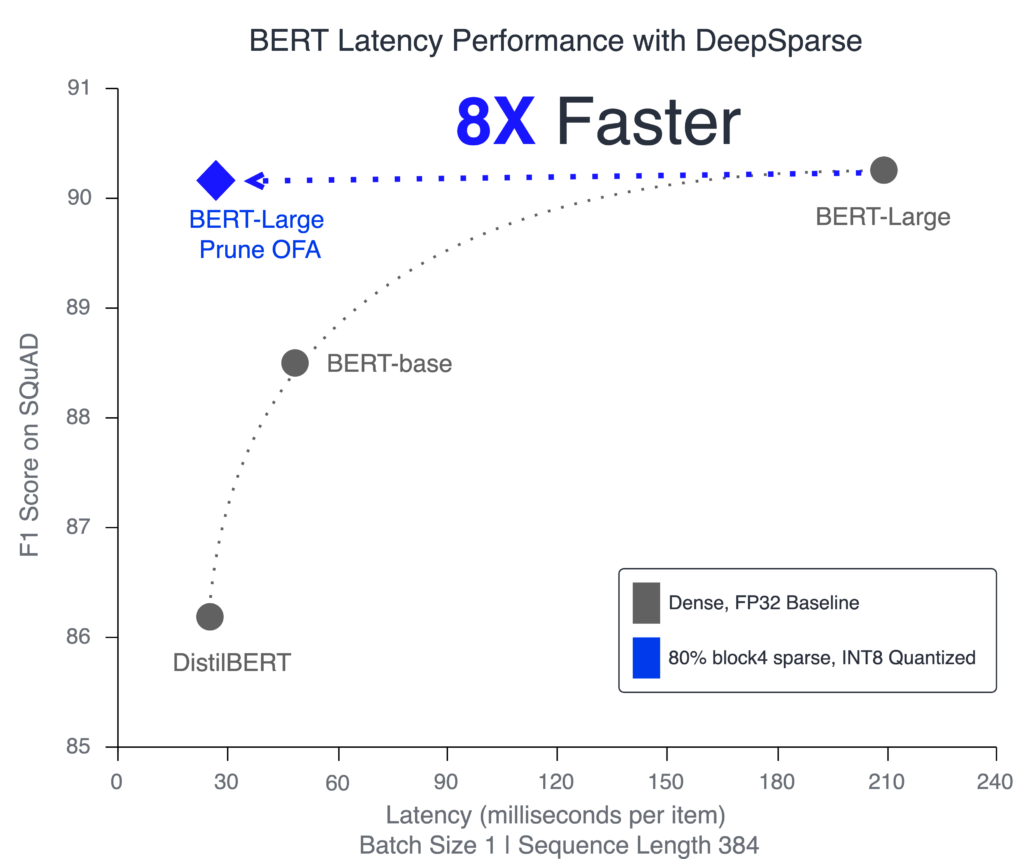
BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic

arxiv-sanity