
Red Pajama 2: The Public Dataset With a Whopping 30 Trillion Tokens
Together, the developer, claims it is the largest public dataset specifically for language model pre-training
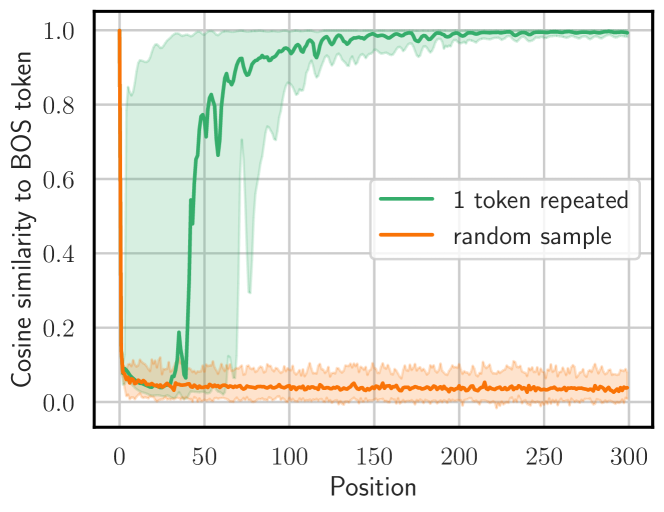
2311.17035] Scalable Extraction of Training Data from (Production) Language Models
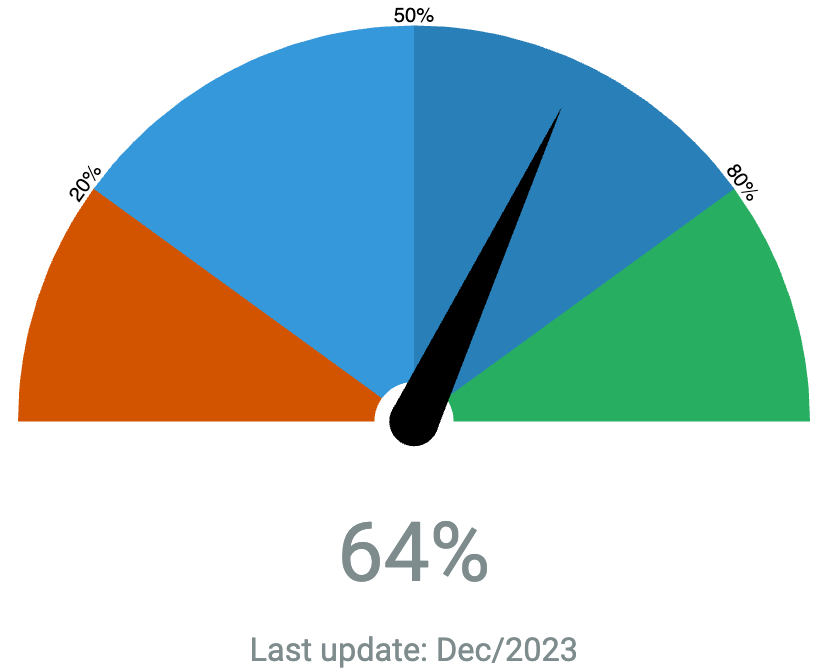
Integrated AI: The sky is comforting (2023 AI retrospective) – Dr Alan D. Thompson – Life Architect
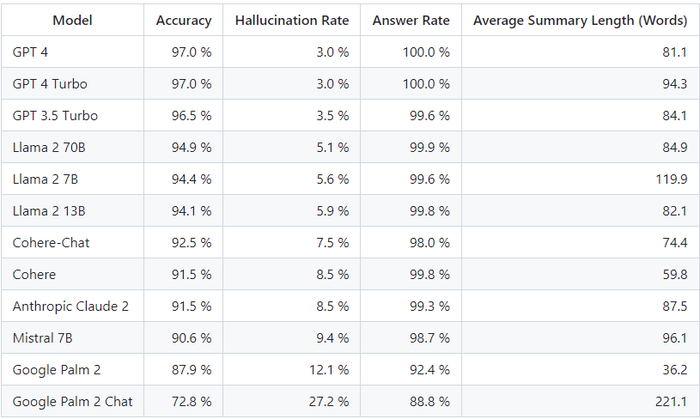
Leaderboard: OpenAI's GPT-4 Has Lowest Hallucination Rate
.png?width=700&auto=webp&quality=80&disable=upscale)
NLP recent news, page 8 of 31

RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens

Shamane Siri, PhD on LinkedIn: RedPajama-Data-v2: an Open Dataset with 30 Trillion Tokens for Training…

Ahead of AI #8: The Latest Open Source LLMs and Datasets

AI releases RedPajama-Data-v2 dataset, Aleksa Gordić posted on the topic
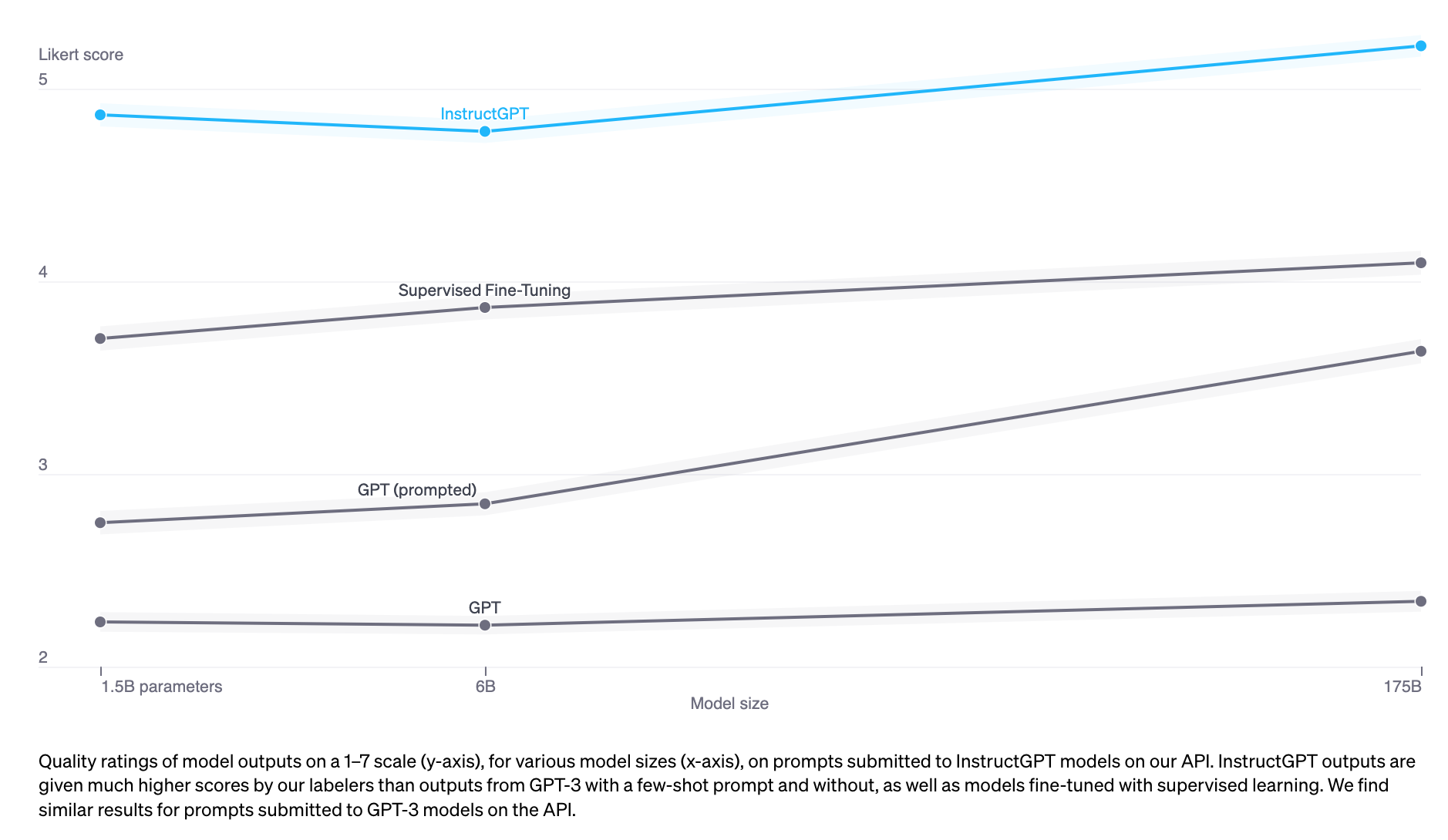
RLHF: Reinforcement Learning from Human Feedback









