
The LLM Triad: Tune, Prompt, Reward - Gradient Flow
As language models become increasingly common, it becomes crucial to employ a broad set of strategies and tools in order to fully unlock their potential. Foremost among these strategies is prompt engineering, which involves the careful selection and arrangement of words within a prompt or query in order to guide the model towards producing theContinue reading "The LLM Triad: Tune, Prompt, Reward"
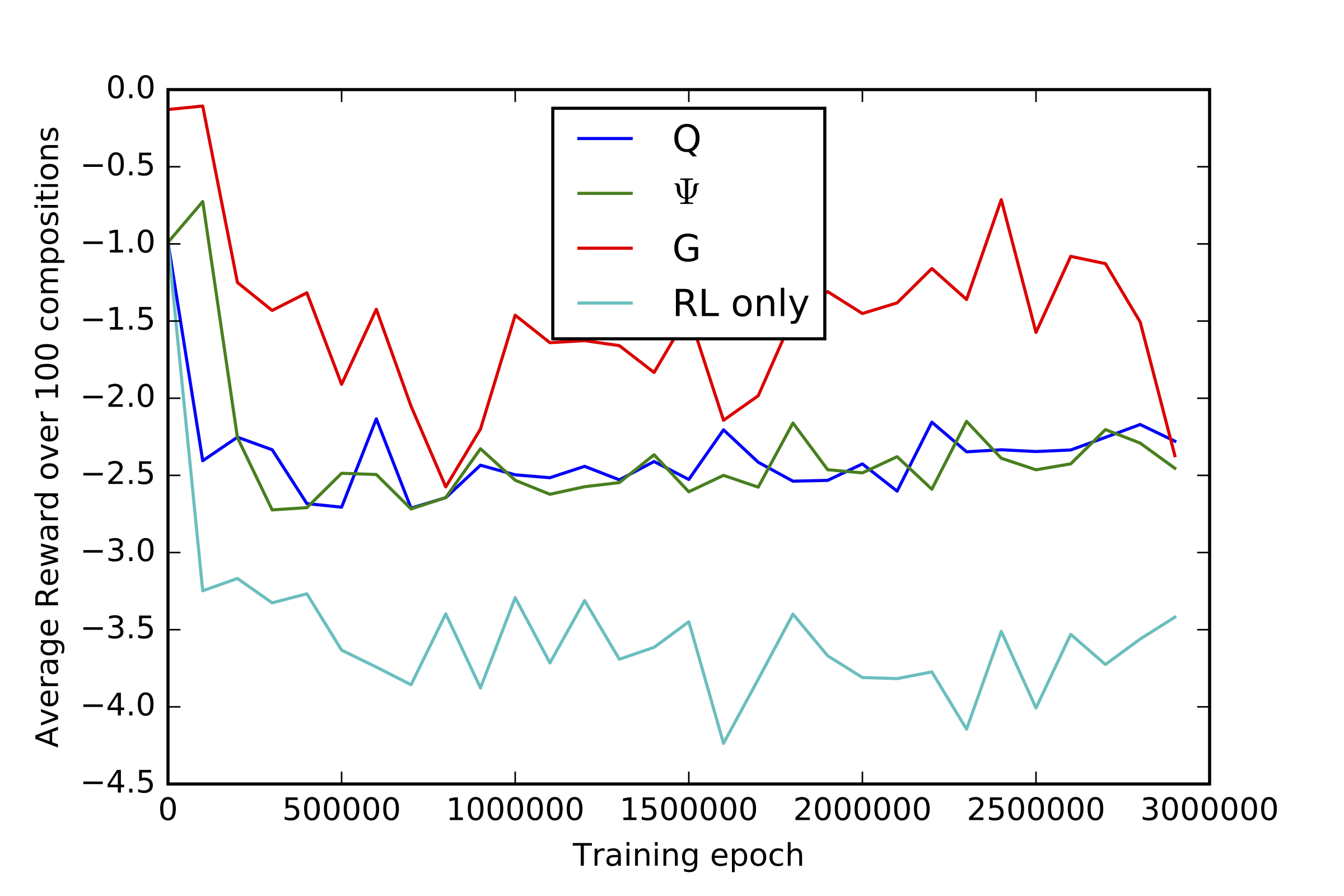
Tuning Recurrent Neural Networks with Reinforcement Learning

HOW TO USE RLHF TO FINE-TUNE YOUR DATA ON GOOGLE CLOUD PLATFORM USING LLAMA-2, by Nnaemeka Nwankwo

Applied Sciences March-1 2024 - Browse Articles

Gradient Flow

RLHF + Reward Model + PPO on LLMs, by Madhur Prashant

2023 Australasian Anaesthesia – Blue Book by anzca1992 - Issuu

Some Core Principles of Large Language Model (LLM) Tuning, by Subrata Goswami

Building an LLM Stack Part 3: The art and magic of Fine-tuning

Some Core Principles of Large Language Model (LLM) Tuning, by Subrata Goswami

Building an LLM Stack Part 3: The art and magic of Fine-tuning

Open-Source LLM Explained: A Beginner's Journey Through Large Language Models, by ByFintech @ AI4Finance Foundation

Gradient Flow Snapshot





)