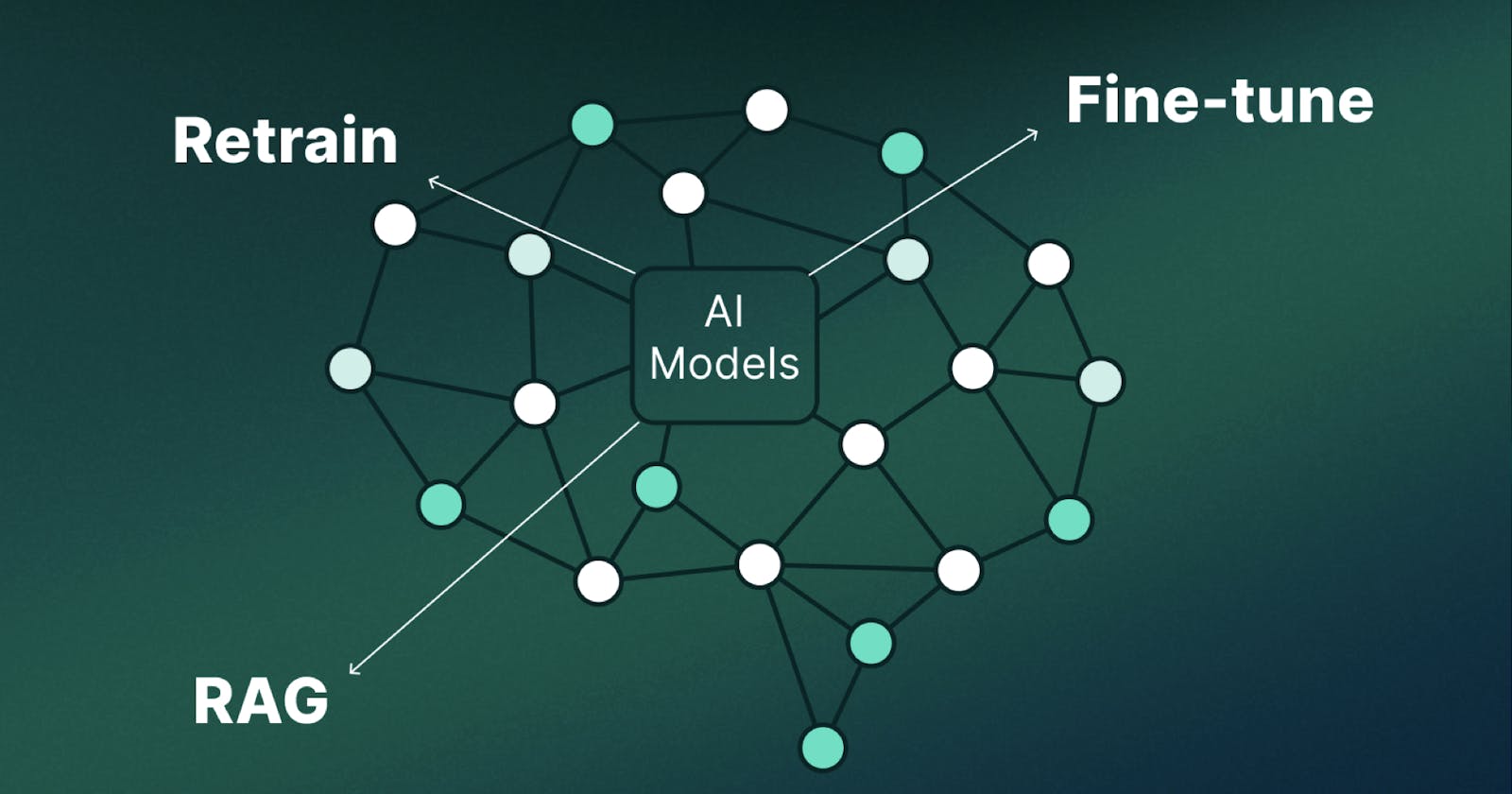
Reinforcement Learning as a fine-tuning paradigm
Reinforcement Learning should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose foundation models, rather than a paradigm that can bootstrap intelligence from scratch.
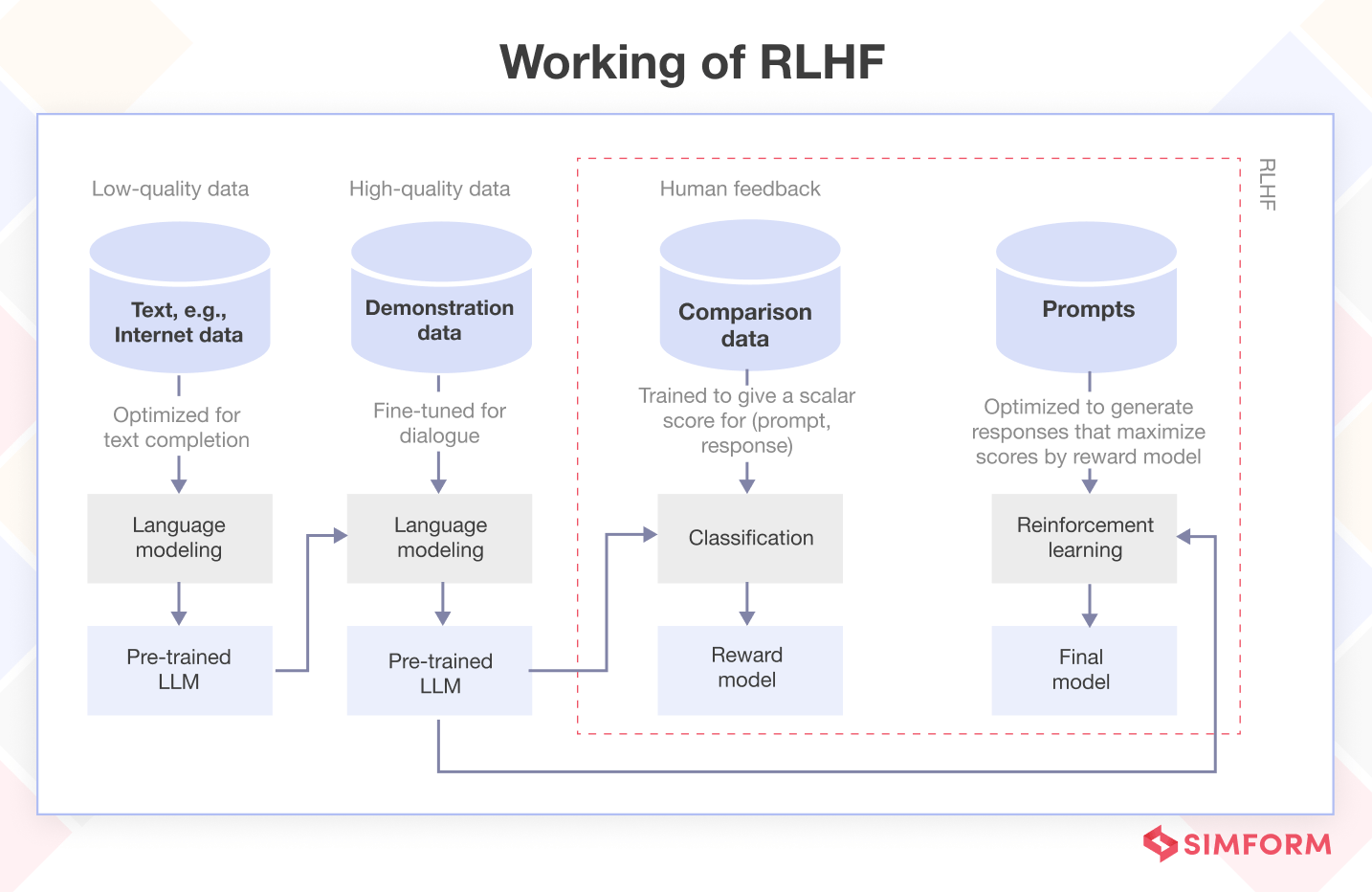
What is Reinforcement Learning from Human Feedback (RLHF)?
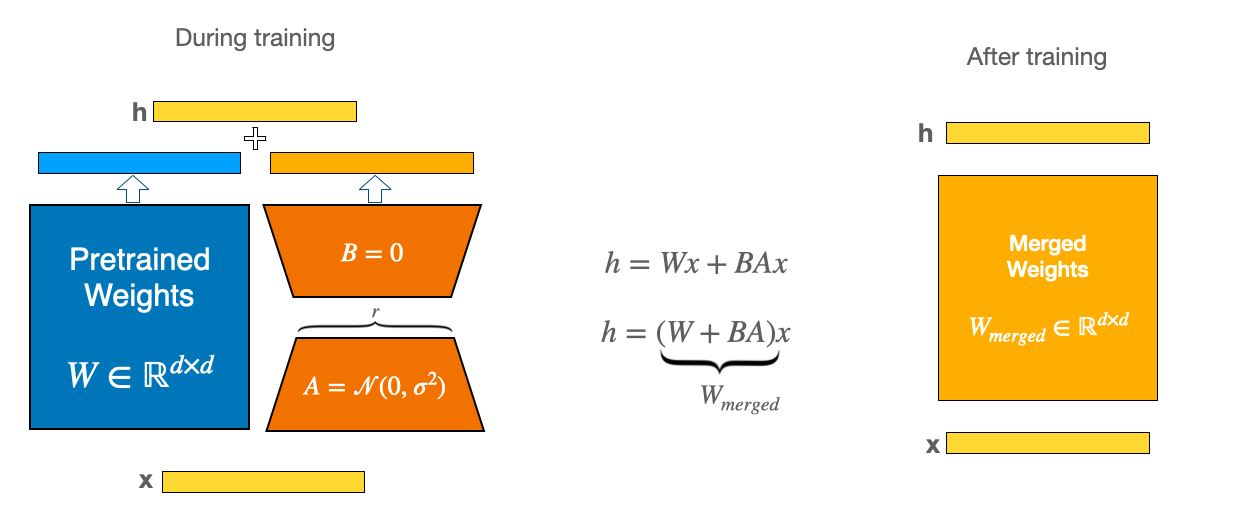
Efficient Model Fine-Tuning for LLMs: Understanding PEFT by

Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
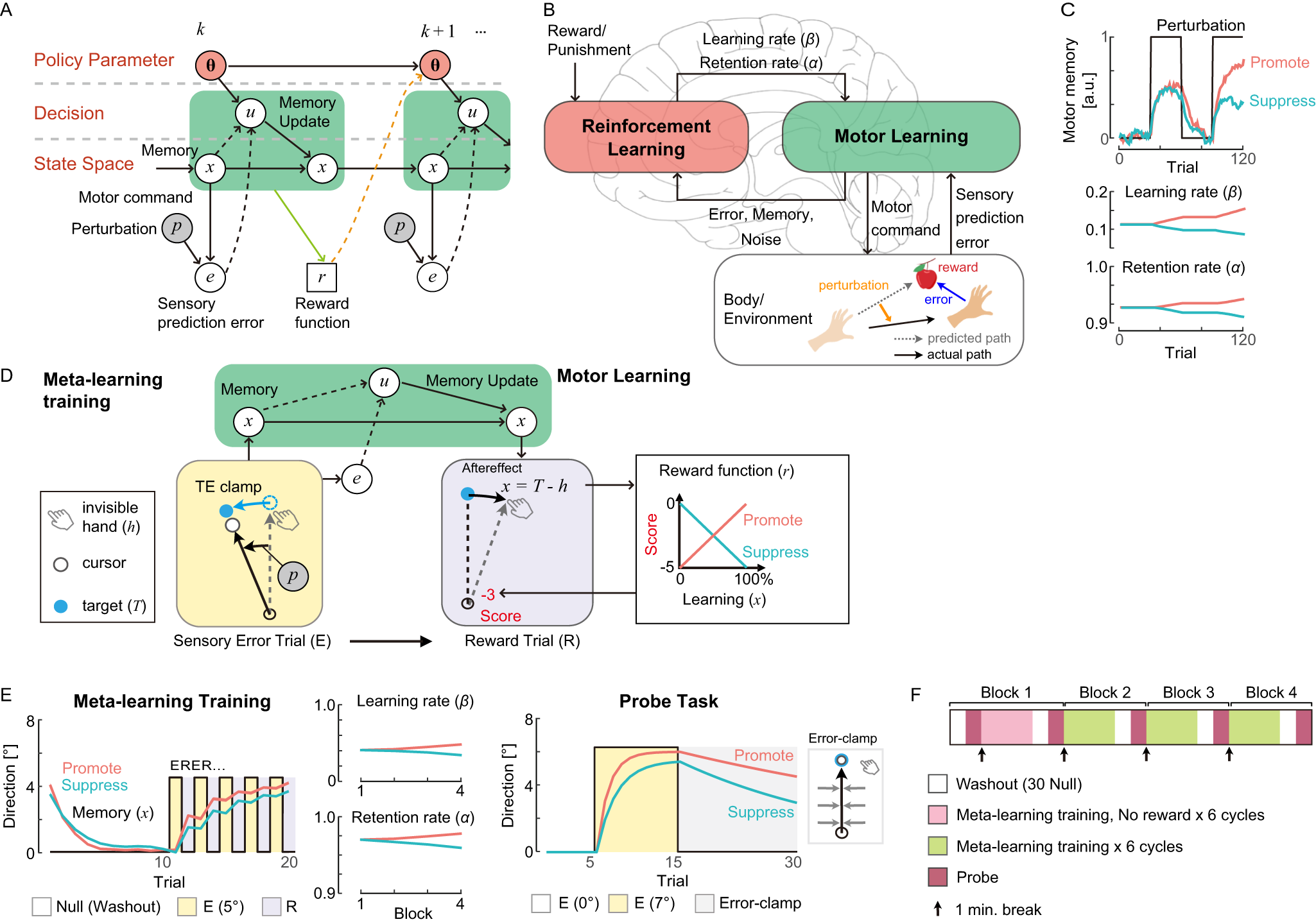
Reinforcement learning establishes a minimal metacognitive process
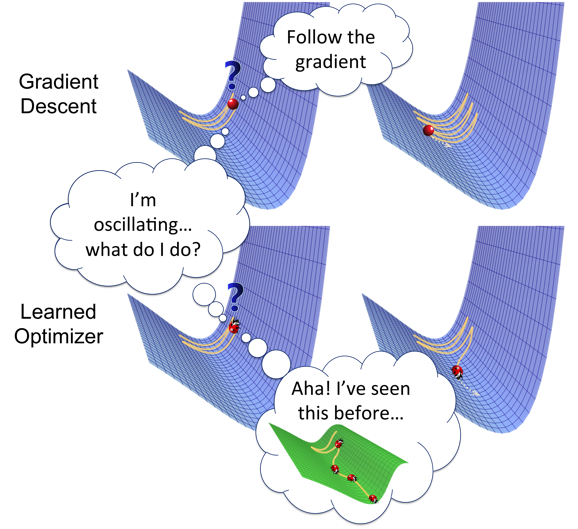
Learning to Optimize with Reinforcement Learning – The Berkeley

Fine-Tuning Language Models Using Direct Preference Optimization
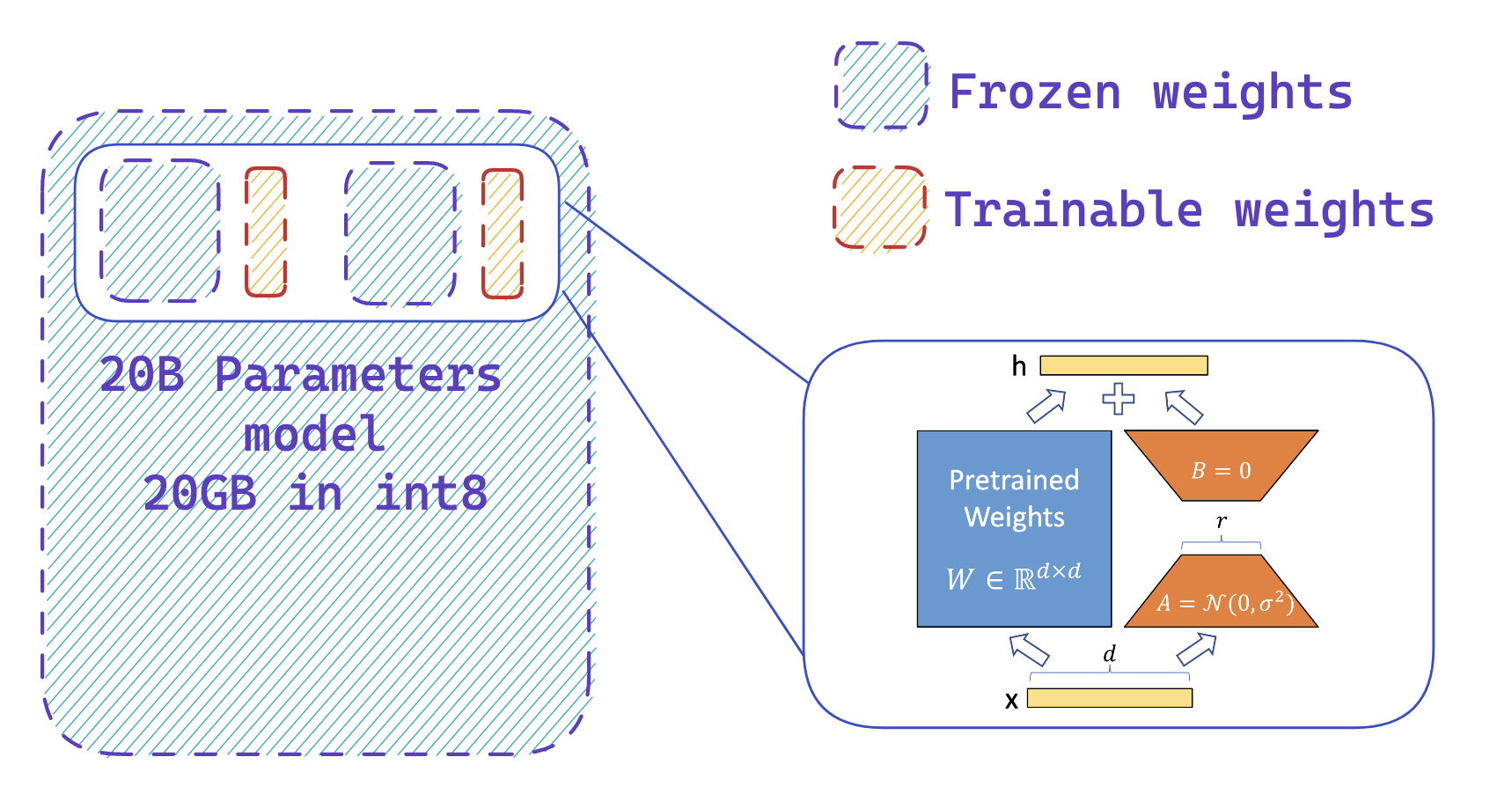
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

Spectra - A New Paradigm for Exploiting Pre-trained Model Hubs
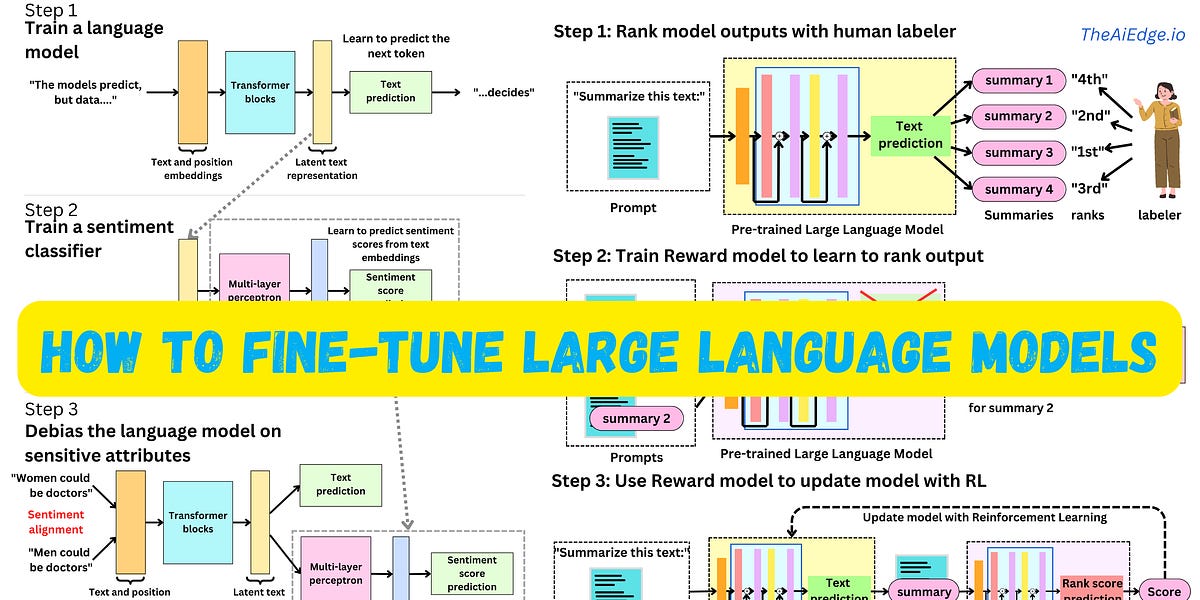
The AiEdge+: How to fine-tune Large Language Models with Intermediary models

PDF] Active Finetuning: Exploiting Annotation Budget in the