DistributedDataParallel non-floating point dtype parameter with
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re

torch.nn、(一)_51CTO博客_torch.nn

Sharded Data Parallelism - SageMaker

4. Memory and Compute Optimizations - Generative AI on AWS [Book]

Optimizing model performance, Cibin John Joseph

torch.nn、(一)_51CTO博客_torch.nn
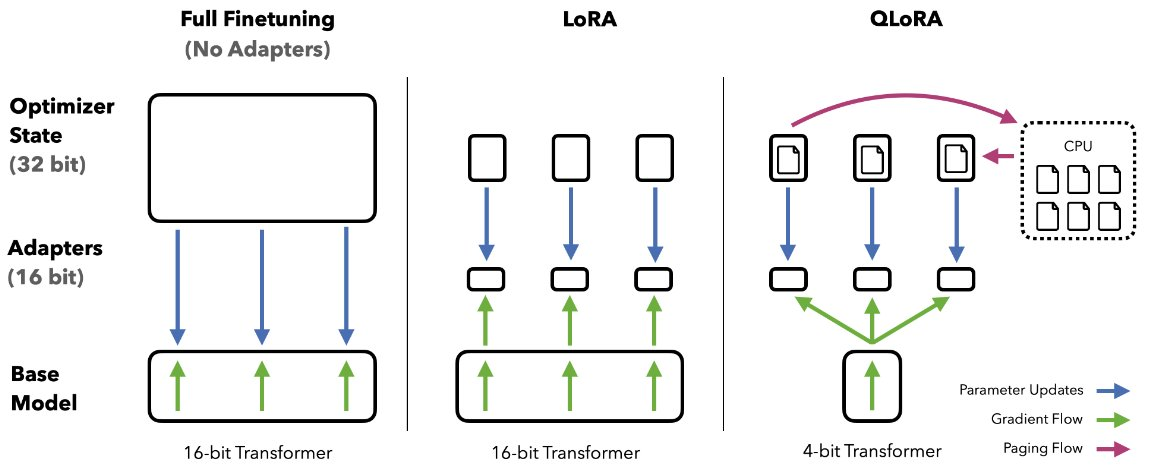
Finetune LLMs on your own consumer hardware using tools from PyTorch and Hugging Face ecosystem

Configure Blocks with Fixed-Point Output - MATLAB & Simulink - MathWorks Nordic

/content/images/size/w350/2022/

torch.nn、(一)_51CTO博客_torch.nn
Error using DDP for parameters that do not need to update gradients · Issue #45326 · pytorch/pytorch · GitHub

distributed data parallel, gloo backend works, but nccl deadlock · Issue #17745 · pytorch/pytorch · GitHub

Distributed PyTorch Modelling, Model Optimization, and Deployment
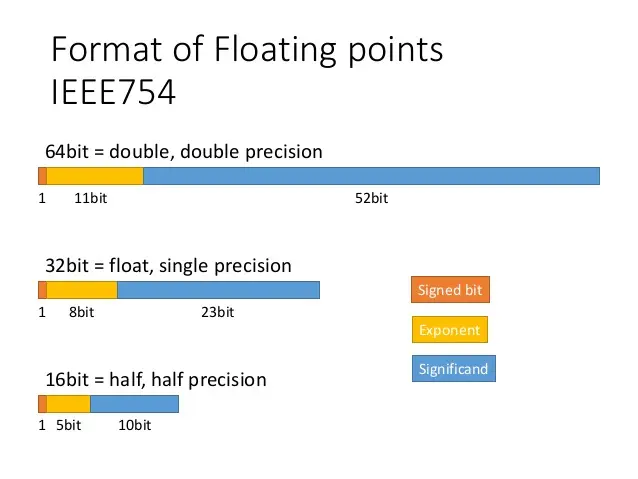
Aman's AI Journal • Primers • Model Compression
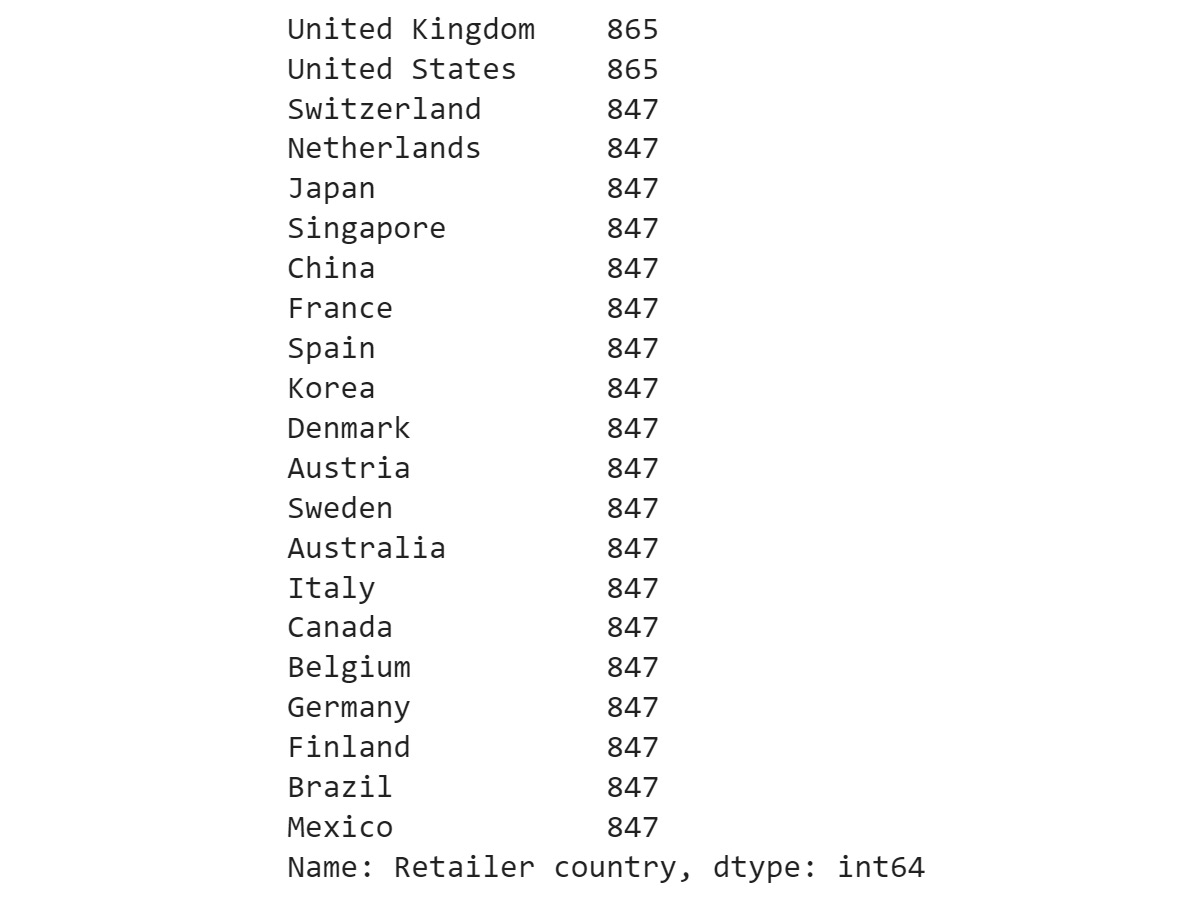
/filters:no_upscale()/articles/overcoming-privacy-challenges-synthetic-data/en/resources/1df-dtypes-1608568363249.jpg)