
Dataset too large to import. How can I import certain amount of rows every x hours? - Question & Answer - QuickSight Community
Im trying to load data from a redshift cluster but the import fails because the dataset is too large to be imported using SPICE. (Figure 1) How can I import…for example…300k rows every hour so that I can slowly build up the dataset to the full dataset? Maybe doing an incremental refresh is the solution? The problem is I don’t understand what the “Window size” configuration means. Do i put 300000 in this field (Figure 2)?

AWS DAS-C01 Practice Exam Questions - Tutorials Dojo

Quicksight: Deep Dive –
QuickSight Now Generally Available – Fast & Easy to Use Business Analytics for Big Data

AWS Quicksight vs. Tableau -Which is The Best BI Tool For You?

Spice import rows skipped - Question & Answer - QuickSight Community

AWS Quicksight vs. Tableau -Which is The Best BI Tool For You?
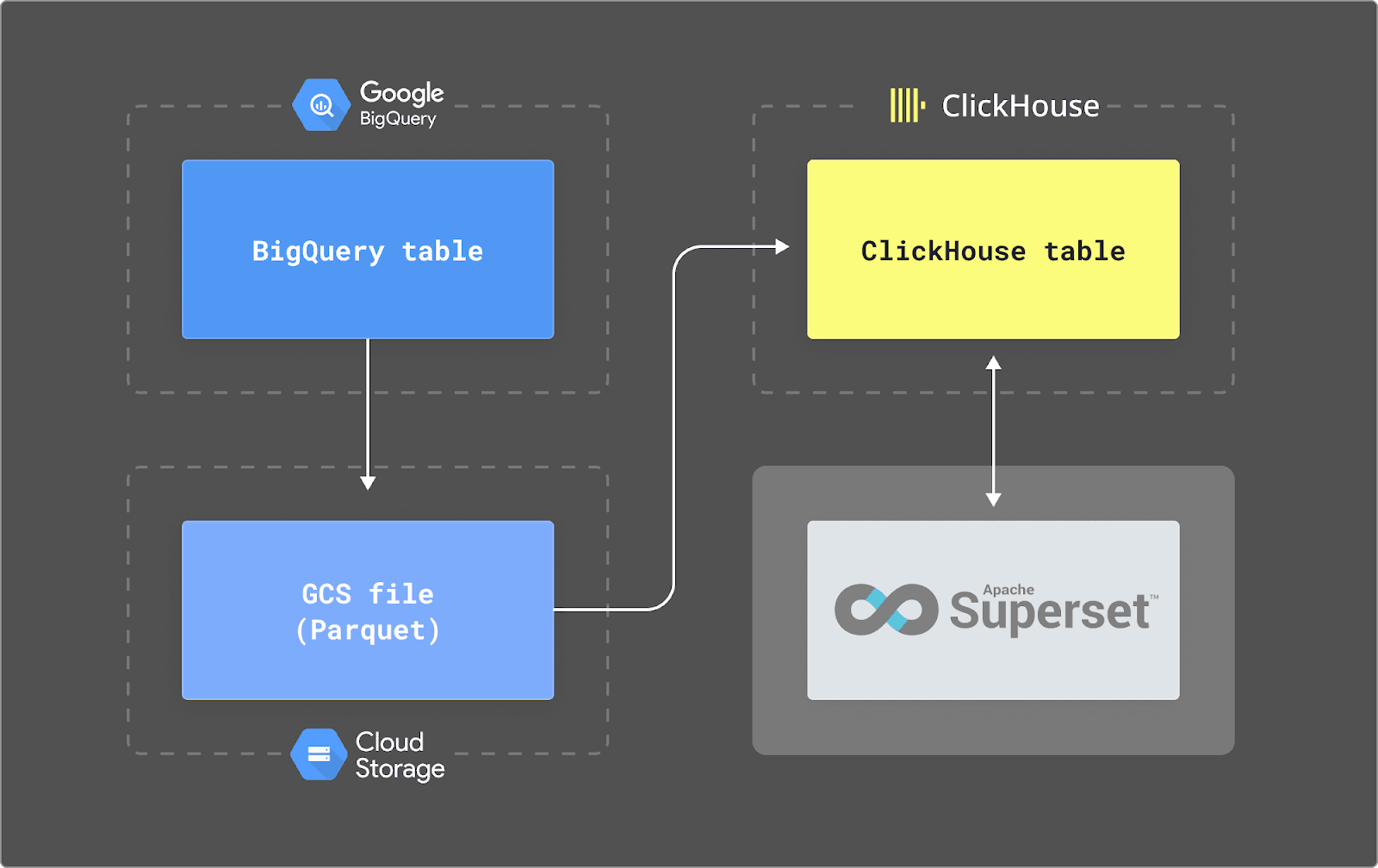
Enhancing Google Analytics Data with ClickHouse

Easy Analytics on AWS with Redshift, QuickSight, and Machine Learning, AWS Public Sector Summit 2016
How to open a very large Excel file - Quora
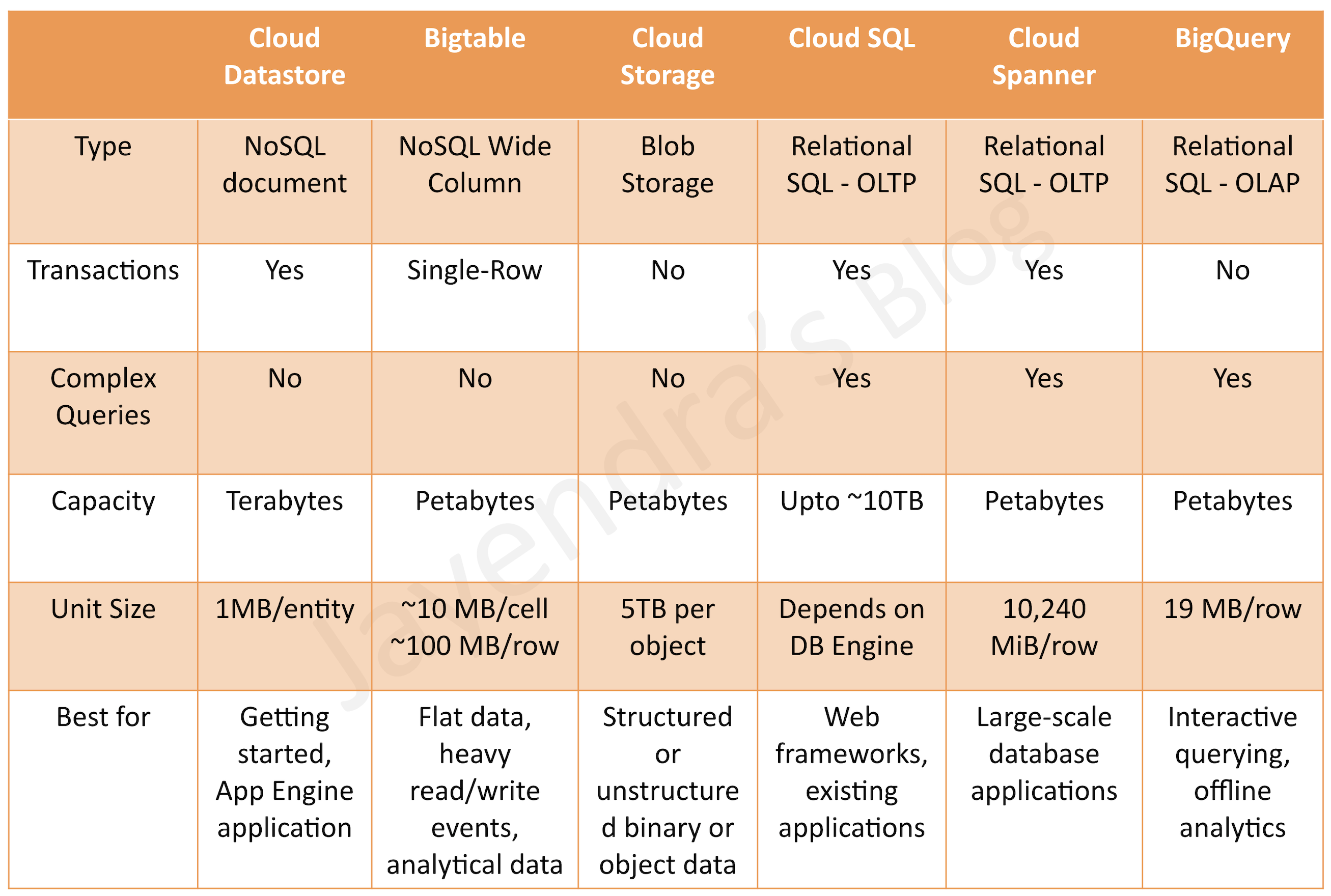
Google Cloud Storage Options

QuickSight
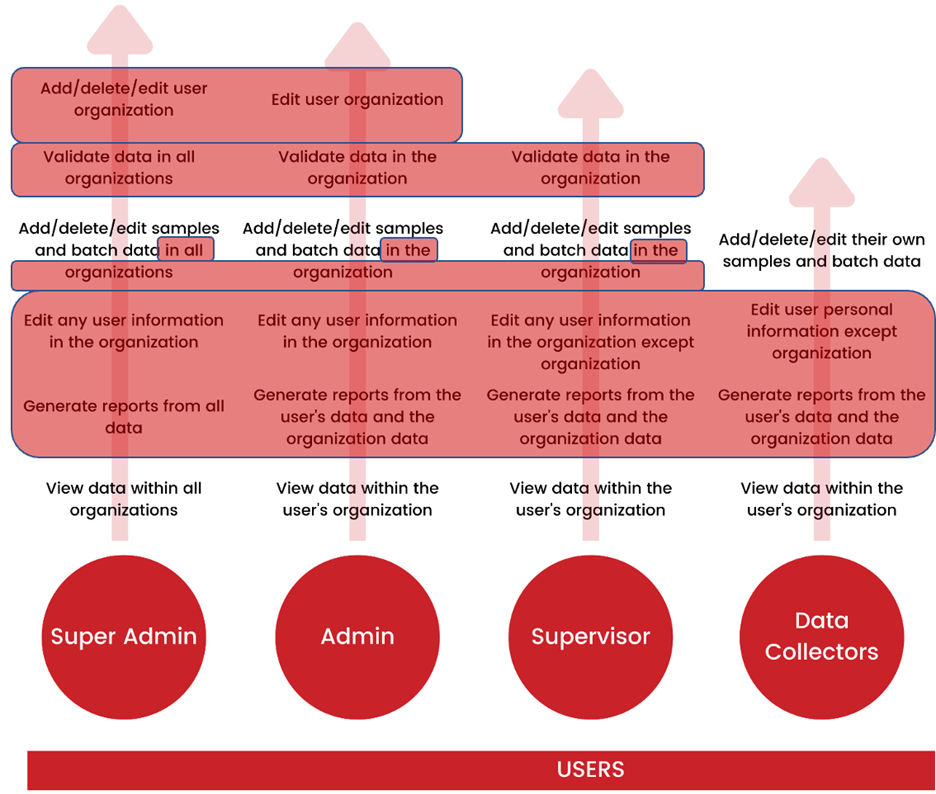
SDC – Projects

QuickSight






)

