DistributedDataParallel non-floating point dtype parameter with requires_grad=False · Issue #32018 · pytorch/pytorch · GitHub
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re
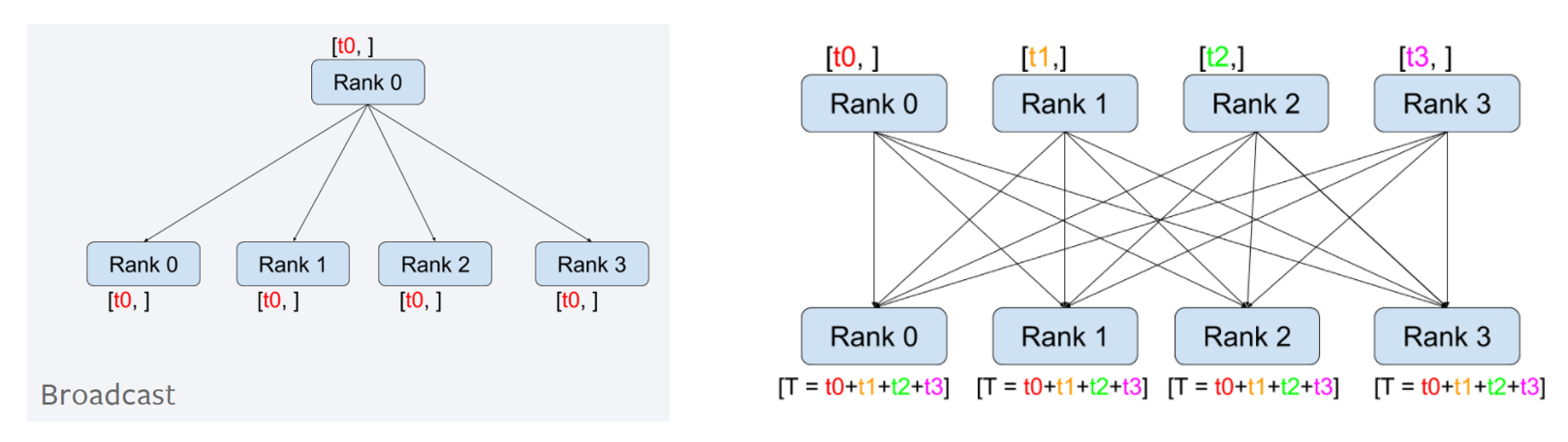
Pytorch - DistributedDataParallel (2) - 동작 원리

How distributed training works in Pytorch: distributed data
when inputs includes str, scatter() in dataparallel won't split
Tensor data dtype ComplexFloat not supported for NCCL process

More In-Depth Details of Floating Point Precision - NVIDIA CUDA
AzureML-BERT/pretrain/PyTorch/distributed_apex.py at master

Wrong gradients when using DistributedDataParallel and autograd
parameters() is empty in forward when using DataParallel · Issue

Distributed data parallel and distributed model parallel in







