We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on

PDF] Masked Siamese ConvNets

The freeze out distribution, f f ree (x, p), in the Rest Frame of the

PDF] ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders

openi_paper/pytorch-image-models: PyTorch image models, scripts, pretrained weights -- ResNet, ResNeXT, EfficientNet, EfficientNetV2, NFNet, Vision Transformer, MixNet, MobileNet-V3/V2, RegNet, DPN, CSPNet, and more - pytorch-image-models - OpenI - 启

We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on

Implementing ConvNext in PyTorch.
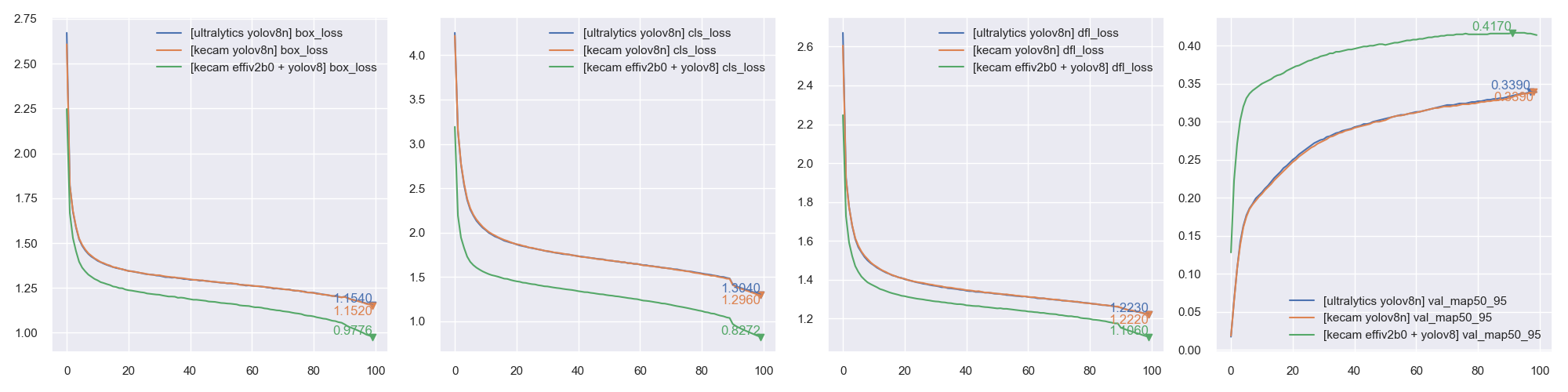
GitHub - leondgarse/keras_cv_attention_models: Keras beit,caformer,CMT,CoAtNet,convnext,davit,dino,efficientdet,edgenext,efficientformer,efficientnet,eva,fasternet,fastervit,fastvit,flexivit,gcvit,ghostnet,gpvit,hornet,hiera,iformer,inceptionnext,lcnet

PDF) How to Fine-Tune Vision Models with SGD

D] Why Vision Tranformers? : r/MachineLearning
We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on
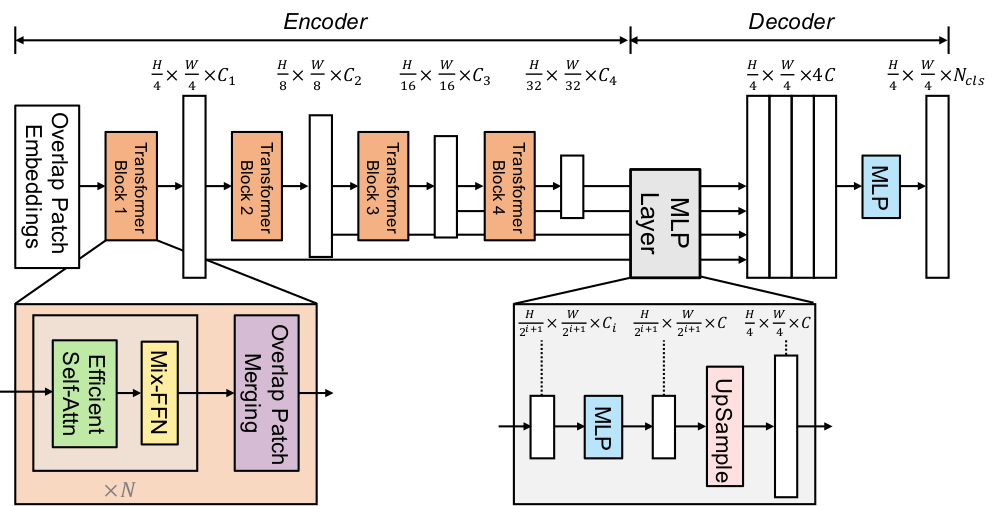
SegFormer
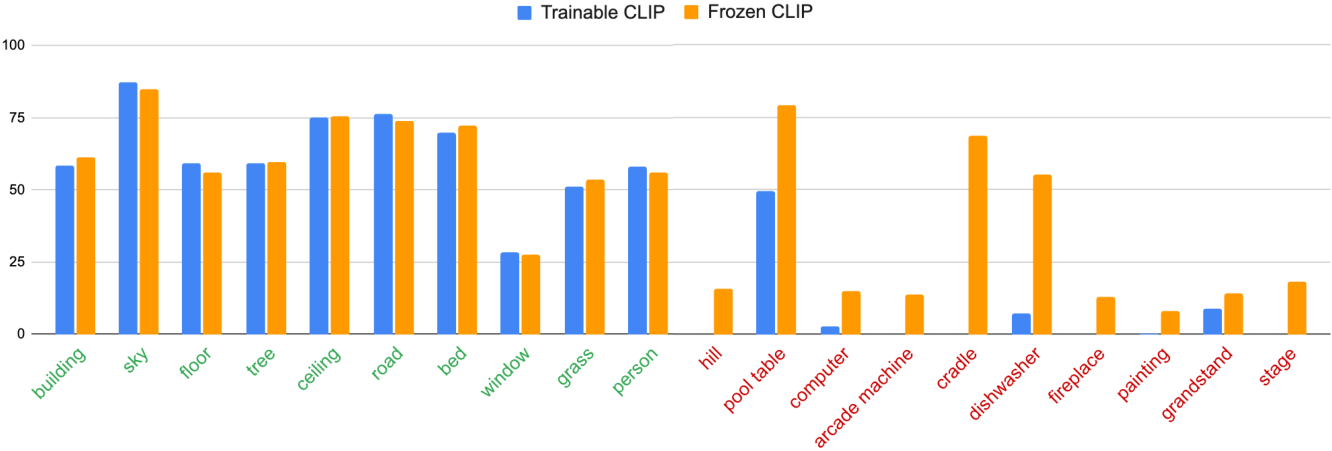
NeurIPS 2023