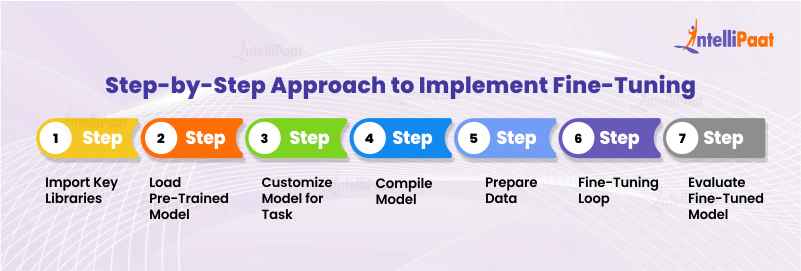
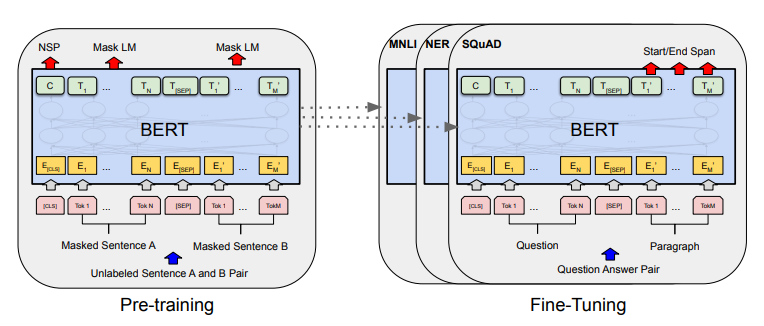
Overview of our two-stage fine-tuning strategy. We run prompt-tuning at
4.6
(391)
Write Review
More
$ 32.00
In stock
Description

Overview of our two-stage fine-tuning strategy. We run prompt

Unlocking the Potential of Prompt Flow: An Illustrative Example of
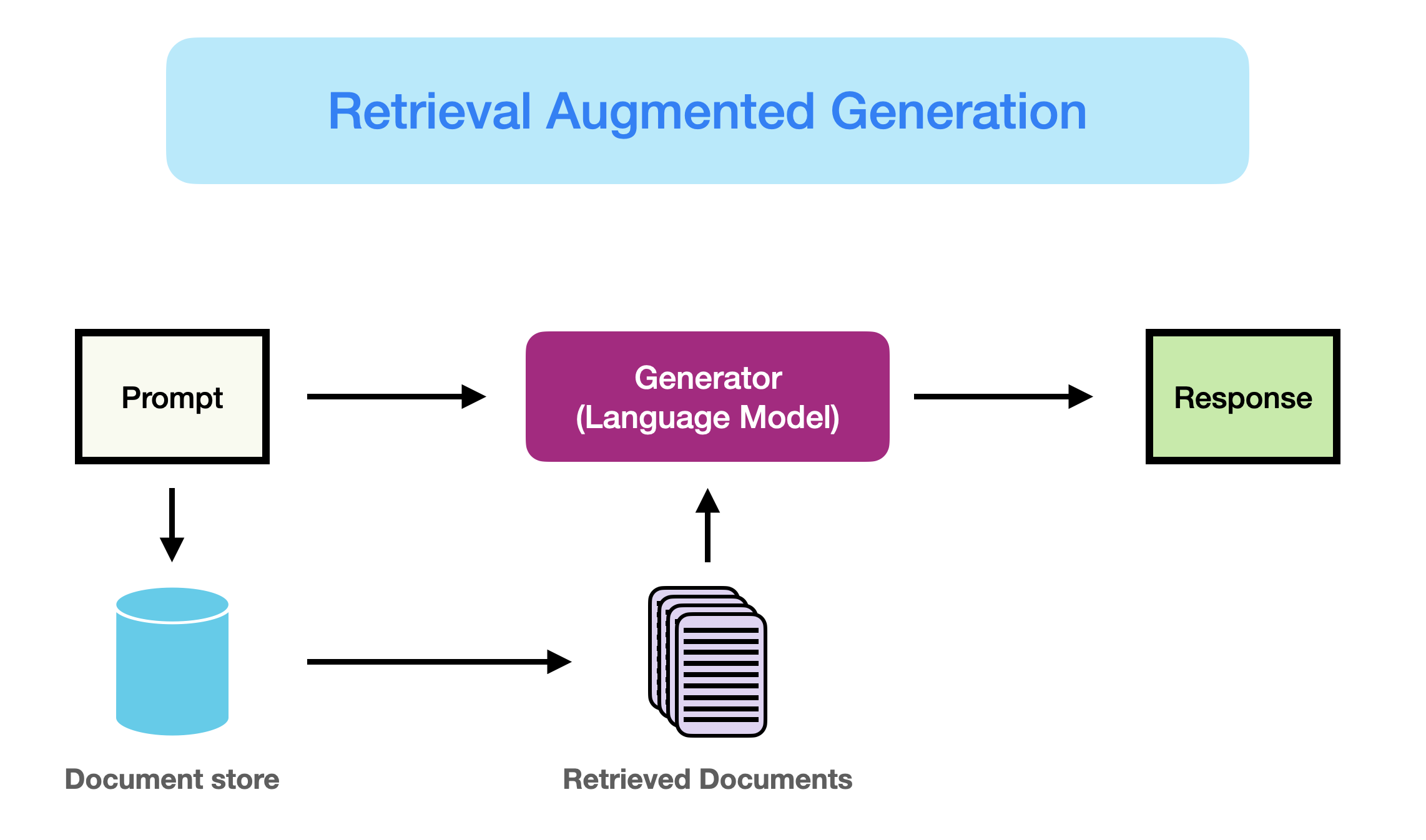
Retrieval Augmented Generation (RAG) for LLMs

EI-CLIP Entity-aware Interventional Contrastive Learning for E-commerce Cross-mo_哔哩哔哩_bilibili
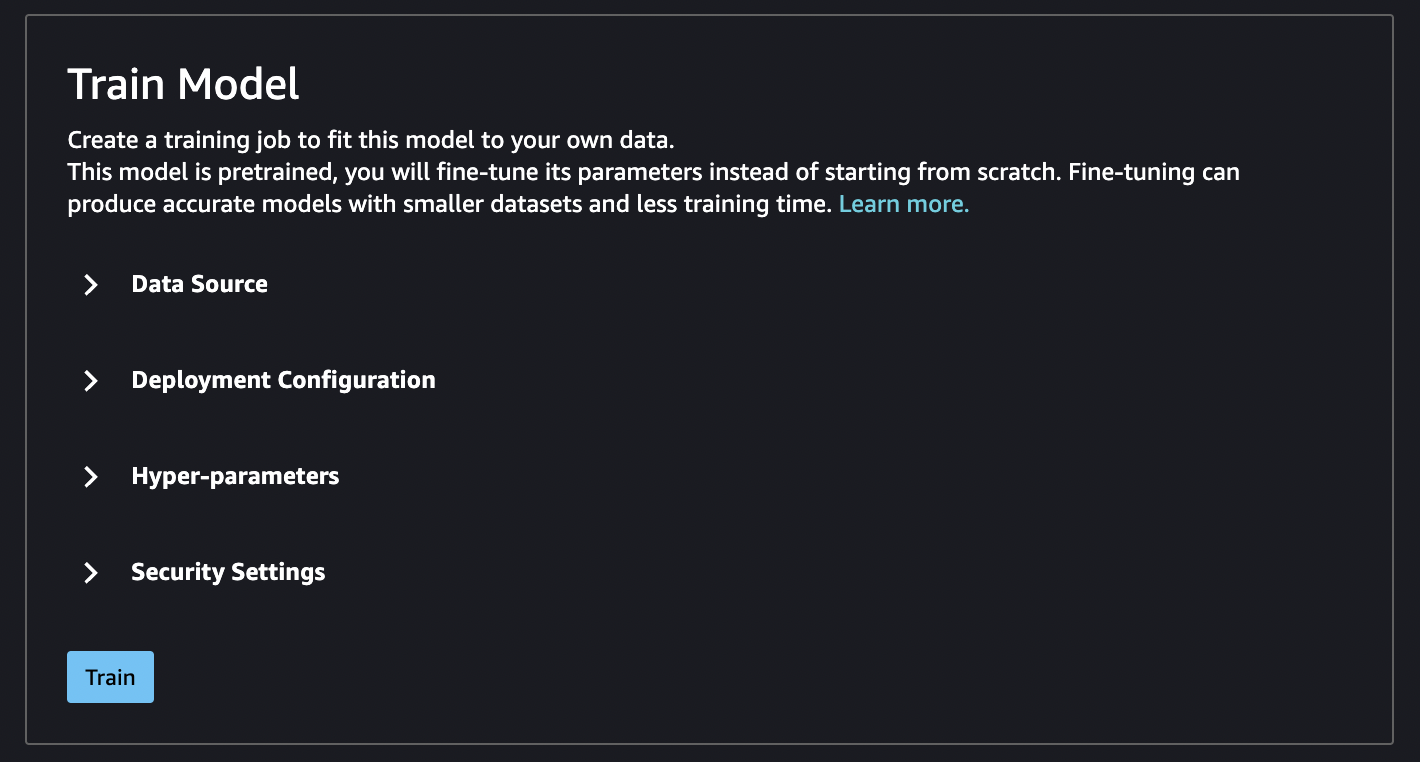
Fine-Tune a Model - SageMaker

A Beginner's Guide to Fine-Tuning Mixtral Instruct Model, by Adithya S K

Applied Sciences, Free Full-Text

The LLM Triad: Tune, Prompt, Reward - Gradient Flow
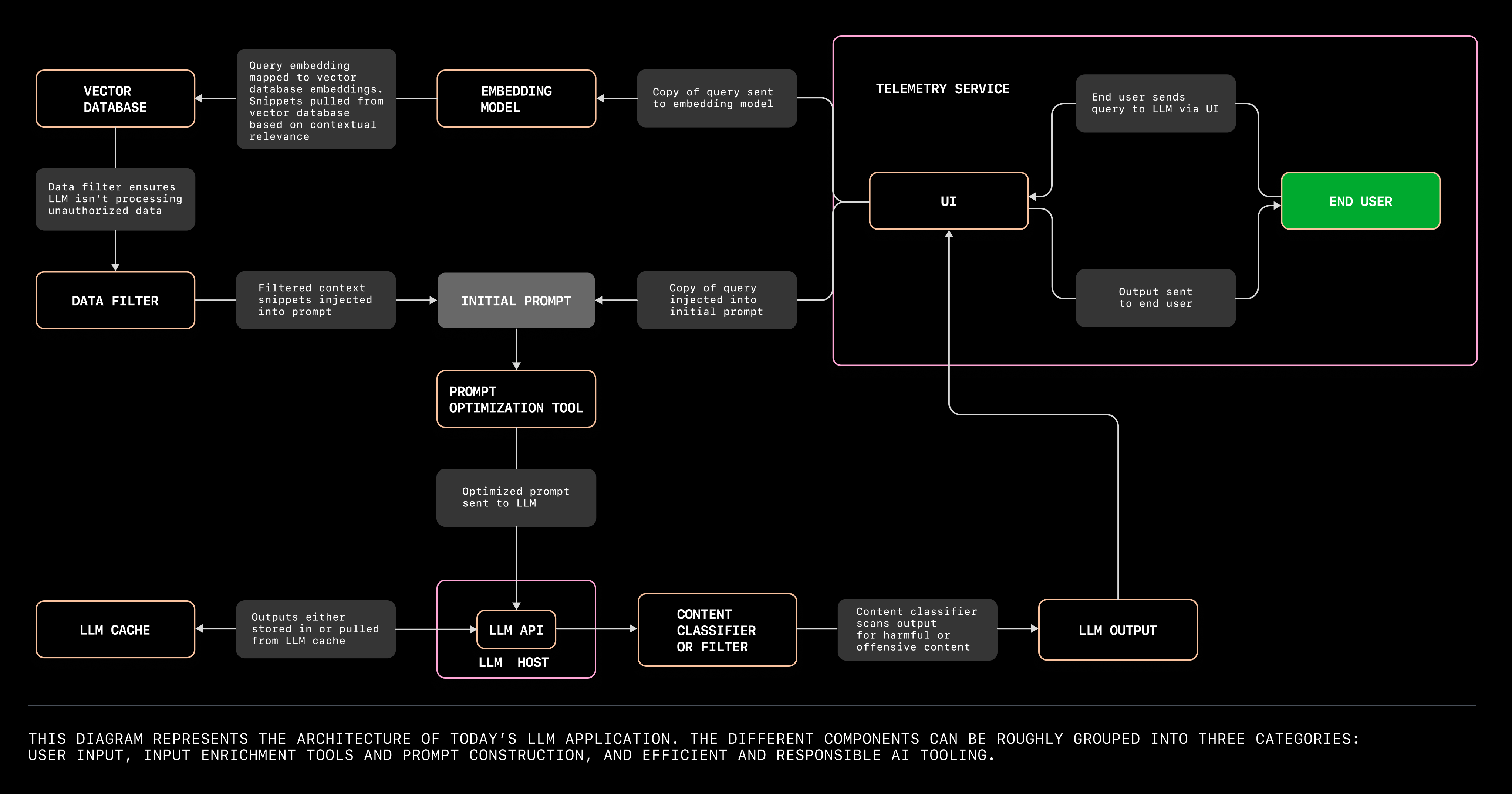
The architecture of today's LLM applications - The GitHub Blog

DINO-GPT4-V: Use GPT-4V in a Two-Stage Detection Model
Cho-Jui HSIEH, University of Texas at Austin, TX, UT, Department of Computer Science

Cho-Jui HSIEH, University of Texas at Austin, TX, UT, Department of Computer Science